PRTG allows you to create dependencies between multiple devices. This allows in case of failure of a device to pass the others automatically paused. This parameter can be used with servers and a switch.
In this tutorial, we will use it to bind a server to a database instance. If on a server, there are several Oracle / SQL Server instances, it is not possible to supervise them on the same device, because the connection information to the instance (credential/ port ….) is linked to equipment.
Prerequisites
- Have created and configured the parent device as well as the sensors.
- Create the equipment linked.
Configuration of dependent equipment
1. On the equipment, click Settings 1 .
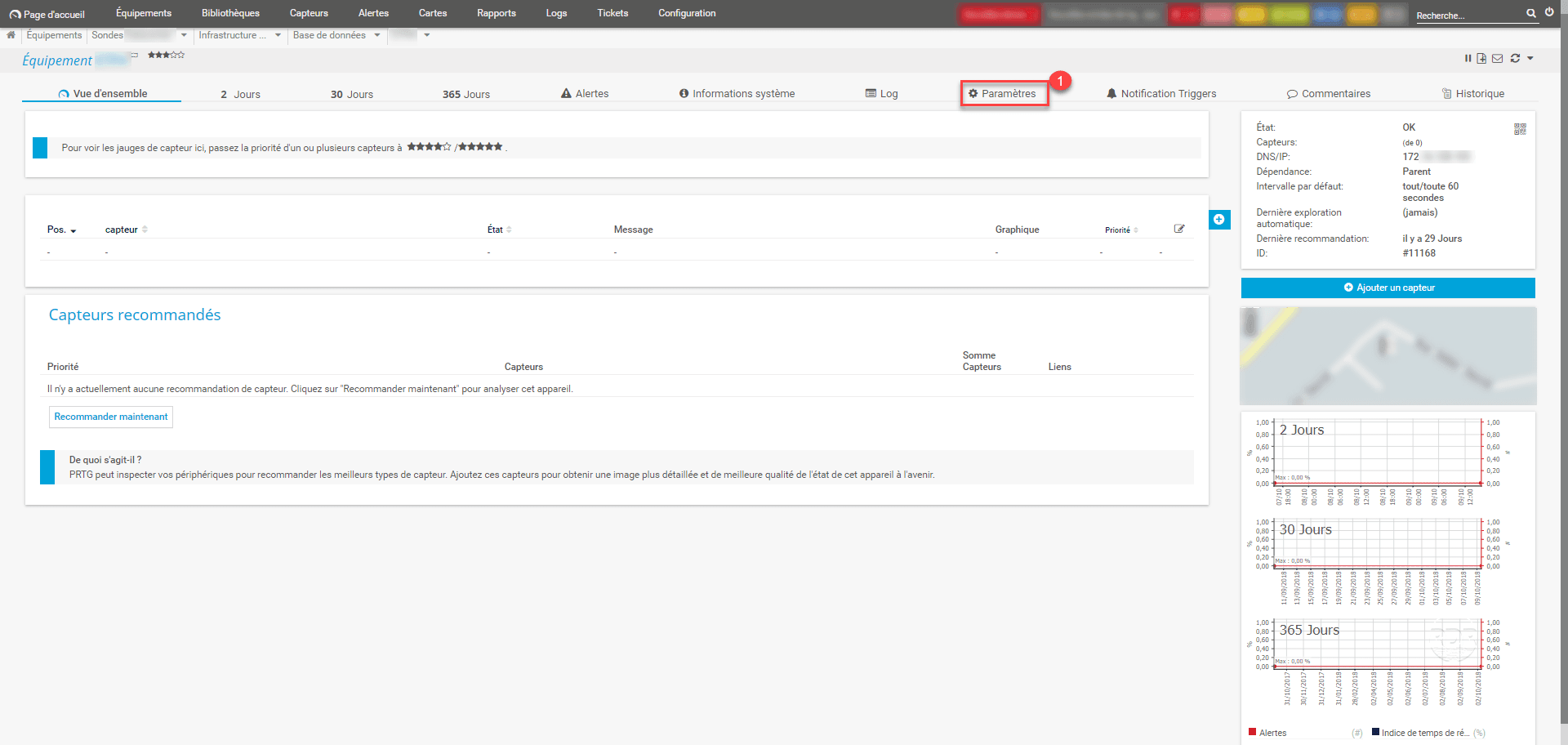
2. Disable the 1 inheritance of Schedule, dependencies and maintenance window, Dependency type choose Select object 2 and click on Click to select a 3 object.
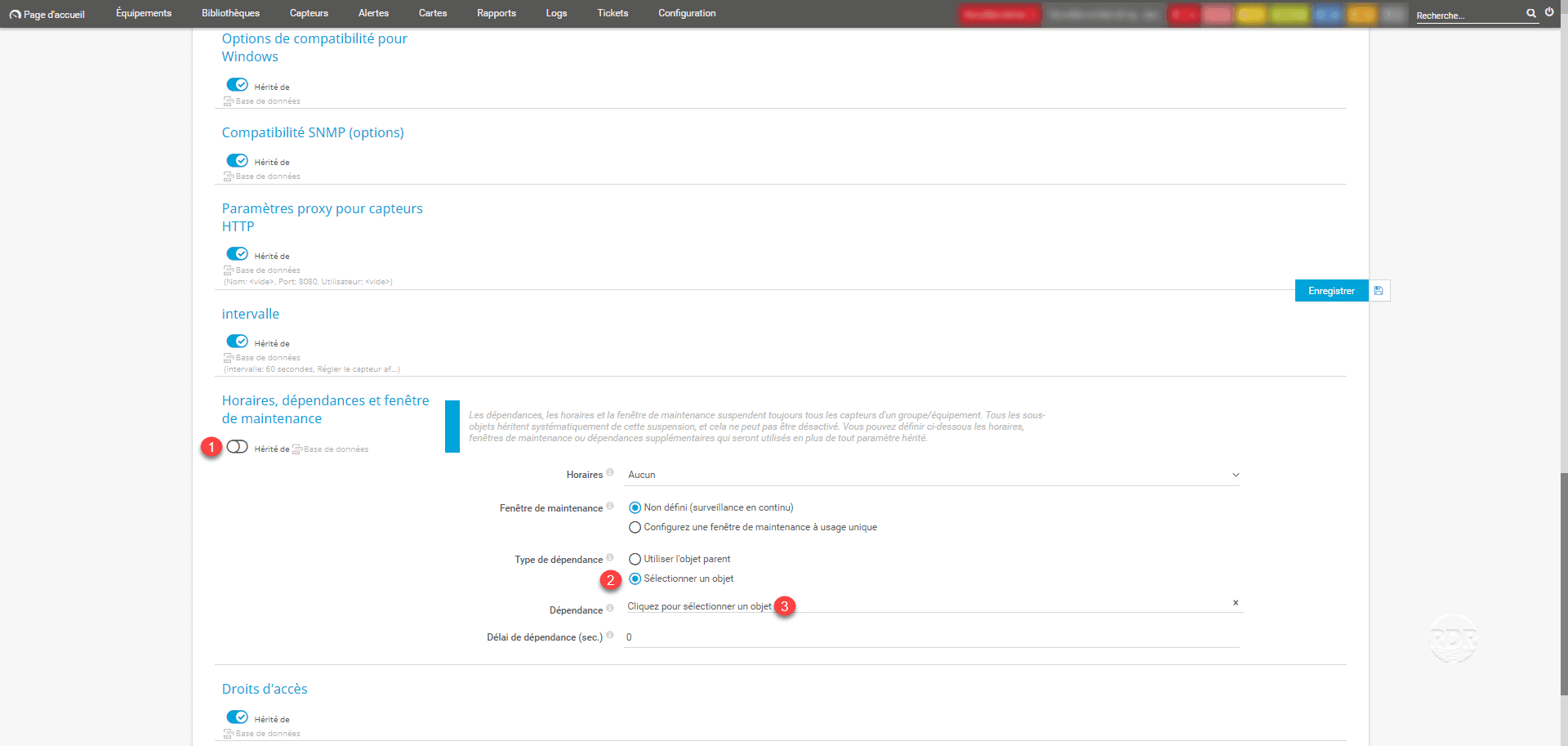
3. Select parent device 1 and sensor 2 then click Save 3 .

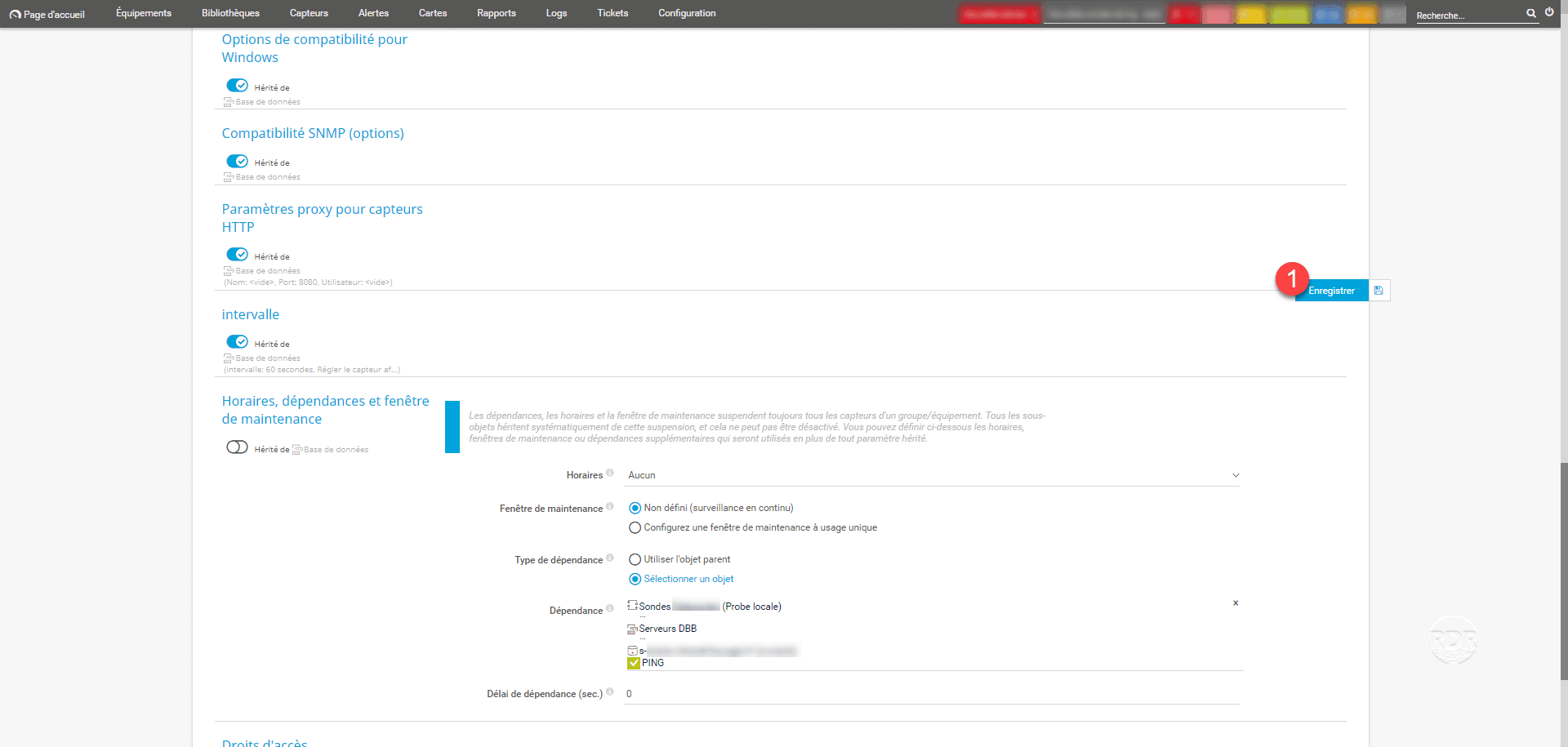
4. Click Save 1 to save the dependency link.
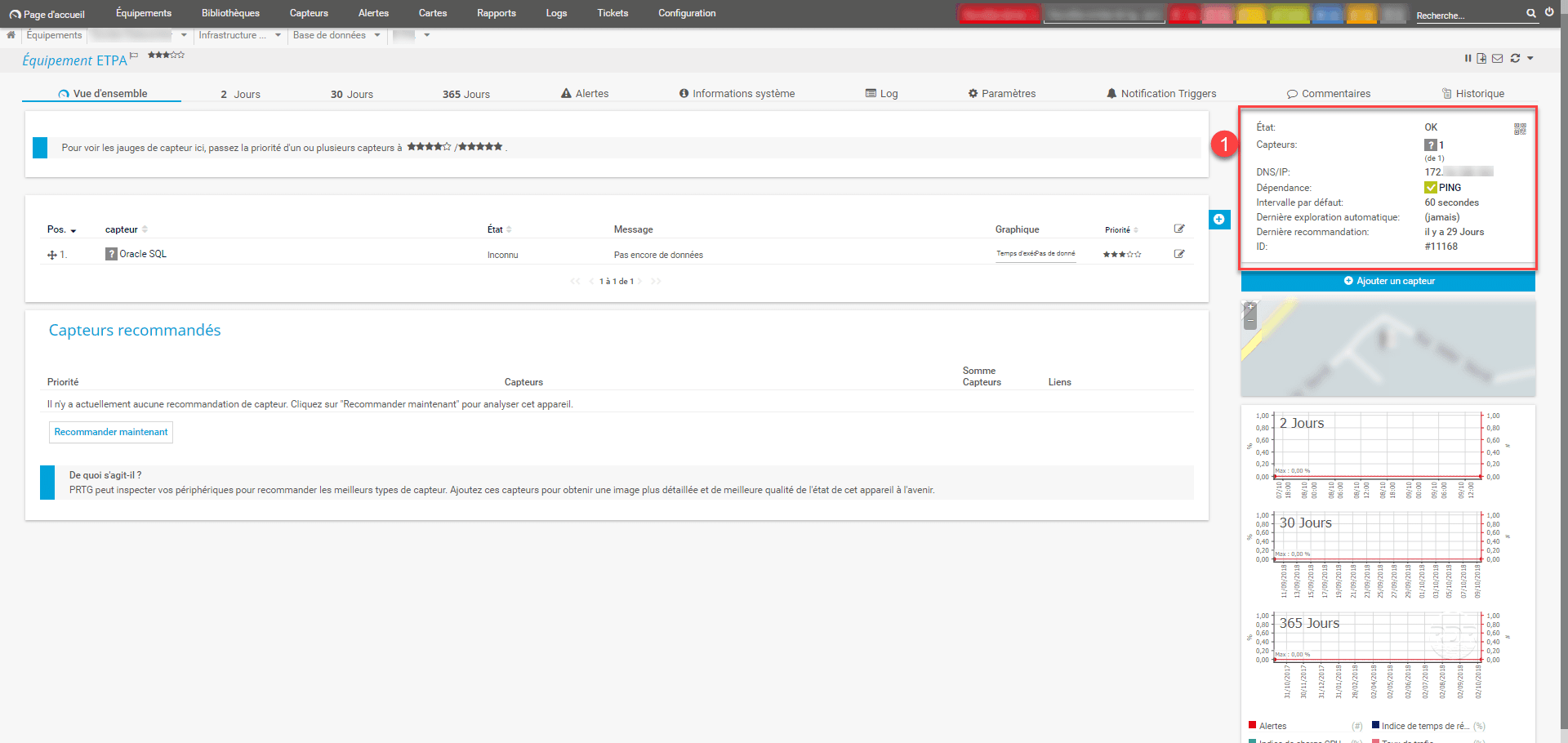
5. The addiction is added. It is visible in the summary of parameters 1 .
Conclusion
The use of the dependency of a parent makes it possible to set up in PRTG a separation in the physical supervision of the server and the software part.
It is necessary to arrive associated equipment as a service and not only like a computer or a material.
