Sur une infrastructure conséquente avec beaucoup de capteurs WMI, il est possible d’avoir des erreurs d’interrogations avec un retour PE015.
Dans cet article, je vais vous expliquer comment surveiller cela et vous mettre sur le chemin de la solution.
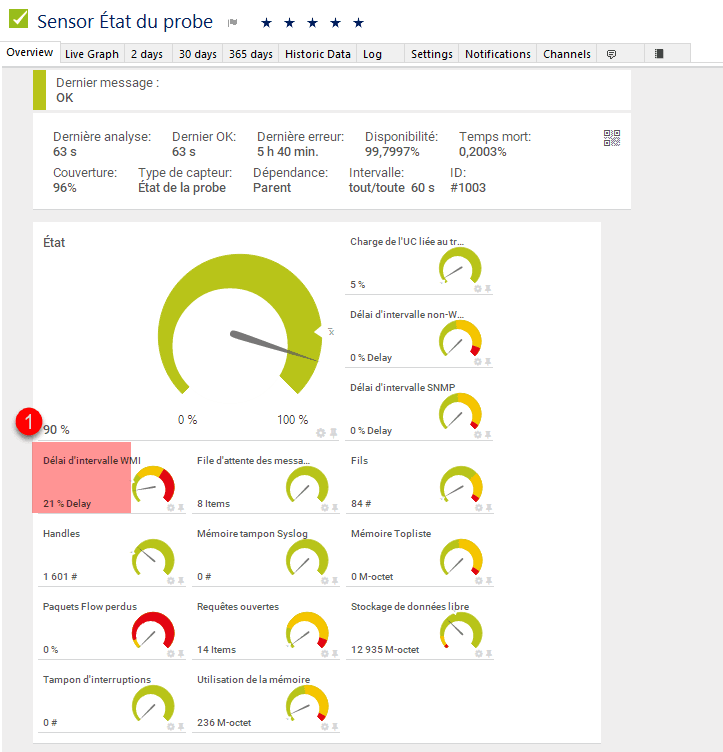
Au niveau de PRTG, il faut regarder sur chaque probe au niveau des capteurs créés automatiquement, celui qui s’appel Etat du probe.
Sur la capture ci-dessous, on peut voir que le canal : Délai d’intervalle WMI 1 et 2 est supérieure à la limite d’alerte avec une valeur à 97%.

Explication : cette valeur correspond au % de temps que la probe met pour effectuer l’ensemble des requêtes WMI dans le temps imparti.
En l’état actuel, si on ajoute un capteur WMI à PRTG, le message d’alerte suivant devrait s’afficher :

Cause
Il existe plusieurs causes à ce comportement :
- Trop grand nombre de capteurs WMI sur une même probe
- Mauvaise optimisation du délai d’intervalle d’interrogation
- Interrogation de machine non disponible (mauvais mot de passe WMI / non disponible en WMI)
Solution
Pour résoudre cette erreur de délai WMI voici plusieurs actions possibles :
- S’assurer que les serveurs configurés en WMI est les bons identifiants que les serveurs soient accessible par ce protocole (exemple : LAN <-> DMZ )
- Modifier l’interval d’interrogation, il n’y a aucun intérêt d’avoir l’espace disque toute les 60sec.
- Utiliser l’interrogation SNMP pour les capteurs suivant à la place des capteurs WMI : CPU/RAM/DISQUES/TRAFIC.
Ceci doit permettre de retourner à une valeur normale 1.