Dans ce tutoriel, je vais vous expliquer comment mettre en place un SIEM avec ELK (Elasticsearch / Logstash / Kibana) avec un Docker.
Avant de se lancer dans le tutoriel, quelques explications et définition sont nécessaire afin de comprendre ce tutoriel.
A la base, le stack ELK devait être installé sur un serveur directement, mais l’utilisation de Docker permet de gagner de beaucoup de temps et facilite le déploiement.
Sommaire
Présentation de ELK et définition de SIEM
ELK ou Elasticsearch/Logstash/Kibana est un stack de logiciel qui permet de mettre en place un SIEM.
Elasticsearch
Pour faire un « simple », Elasticsearch est le moteur de base de données qui va être en charger de stocker et d’indexer les données qui vont être envoyer.
Elasticsearch est prévu pour fonctionner en cluster, c’est à dire avec deux serveurs Elasticsearch ou deux conteneurs.
Il est possible de le faire fonctionner avec un seul nœud mais c’est solution est relativement instable.
Port par défaut : 9200
Logstash
Logstash est logiciel, qui va recevoir les logs, les « transformer » et ensuite les envoyer à Elasticsearch afin que les données soient enregistrés et indexés.
Port par défaut : 5044
Kibana
Kibana est l’interface graphique Web, qui va nous permettre d’accéder aux données qui sont stockés dans Elasticsearch et ainsi d’avoir des tableaux de bords, des graphiques …
En plus de tableau de bord, Kibana permet une analyse des logs afin de détecter certain comportement anormale sur votre environnement.
Port par défaut : 5601
SIEM
Un SIEM (Security Information and Event Management) est un système qui permet de centraliser les logs d’un Système d’Information (Serveurs, Firewall, Equipements réseaux, Application …) et d’en faire des analyse.
Principalement orienté sécurité, l’analyse des logs peut être effectués sur des analyses de performance matériel, système et même applicatif.
Agents Beat
Pour envoyer les données à Logstash puis à Elasticsearch, il existe plusieurs agents qui peuvent être installés sur les serveurs :
- Filebeat : lecture de fichier, principalement utiliser sur Linux pour envoyer le contenu des fichiers logs, il est également utilisé sur Windows pour envoyer les logs IIS par exemple.
- Winlogbeat : agent dédié à Windows qui va lire et envoyer les données des journaux Windows.
- Metricbeat : agent en charge d’envoyer les données de performances du système (CPU, RAM, Disques, Réseaux …)
- Elastic Agent : regroupe les différents agents ci-dessous principalement utiliser pour l’analyse sécurité
- …
Vous trouverez ici la liste des agents : https://www.elastic.co/fr/beats/
Il est possible aussi d’envoyer des informations sans Agents, en utilisant syslog, http …
De nombreux tableaux de bords et modules existent par défaut pour analyser les données.
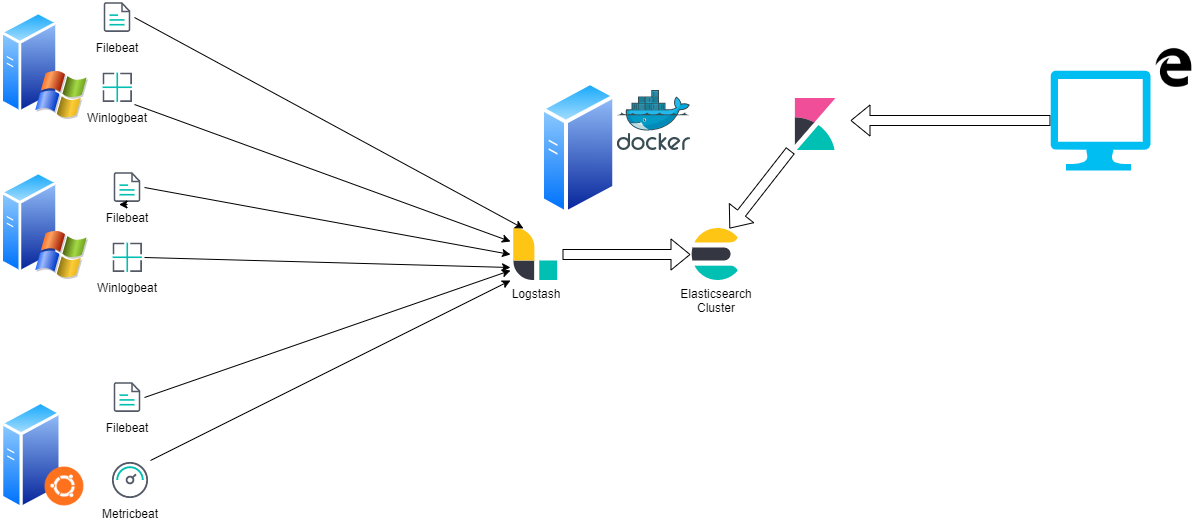
Afin de vous donnez une idée, voici un schéma simplifier de ELK :
Prérequis
Comme expliquer dans le titre et en introduction, nous allons utilisons Docker pour déployer ELK, vous aurez donc besoin d’un serveur Linux avec Docker et docker-compose.
Vous trouverez ici un tutoriel sur l’installation de Docker : https://rdr-it.com/docker-installation-et-utilisation-concrete-sur-ubuntu/installation-de-docker-sur-ubuntu/
Dans ce tutoriel, je vais utiliser le même serveur pour faire fonctionner les 3 services :
- Elasticsearch x2
- Kibana
- Logstash
En fonction de votre environnement (nombre d’agent ou de service qui envoient des logs), il peut être préférable de faire fonctionner Logstash sur un autre serveur.
La première chose, c’est de dédier le serveur à ELK, je vous déconseille de faire fonctionner d’autre conteneur.
En terme de ressource prévoir à minima :
- 4 CPU
- 8 Go de Ram
- Espace disque : 300 Go
Cette configuration est donnée à minima, elle va principalement de la quantité de logs à traiter, plus que de la quantité d’agents ou équipement qui vont envoyer de données.
Pour le bon fonctionnement de Elasticsearch, il faut modifier le paramètre de Virtual memory.
Pour une prise en compte immédiate entrer la commande ci-après ;
sysctl -w vm.max_map_count=262144Afin que ce paramètre soit appliqué après un redémarrage du serveur, éditer le fichier /etc/sysctl.conf et ajouter à la fin vm.max_map_count=262144.
Plus d’information ici : https://www.elastic.co/guide/en/elasticsearch/reference/current/vm-max-map-count.html
Si vous n’appliquez pas ce paramètre, les conteneurs Elascticsearch ne démarre pas.
Installation de Elasticsearch et Kibana
On ne va pas réellement procéder à une installation des composants car nous allons utiliser des conteneurs, ce qui permet de gagner beaucoup de temps, une installation manuelle du stack ELK peut facilement prendre une demi journée à une journée complète. Avec les conteneurs en moins d’une heure c’est fait.
Afin de gagner encore plus de temps, j’ai mis à disposition sur mon Gitlab, deux dépôts :
- Elasticsearch / Logstash / Kibana : https://git.rdr-it.com/docker/elk-with-logstash
- Elasticsearch / Kibana : https://git.rdr-it.com/docker/elk
Dans le tutoriel, je vais utiliser le dépôt avec ELK.
Sur le serveur, créer un dossier, se placer dedans et cloner le dépôt souhaité :
ELK :
sudo git clone https://git.rdr-it.com/docker/elk-with-logstash.git .EK :
sudo git clone https://git.rdr-it.com/docker/elk.git .Le . à la fin de la commande évite la création d’un sous dossier portant le nom de dépôt.
Pour le moment, nous allons nous occuper de Elasticsearch et Kibana.
Il faut éditer le fichier.env afin de configurer le mot de passe du compte elastic. Modifier la valeur du paramètre ELASTIC_PWD qui a pour valeur changeme_please.
Vous pouvez aussi modifier la paramètre version en fonction des versions disponibles.
Au moment de la rédaction de ce tutoriel, les versions stables sont 7.17.0 et 8.0.0, vous trouverez les tags des versions ici : https://hub.docker.com/_/elasticsearch?tab=tags
Maintenant, nous allons passer à la création des certificats pour le bon fonctionnement du cluster Elasticsearch et de Kibana.
Utiliser la commande ci-dessous pour créer les certificats qui seront enregistrer dans le volume certs qui est attaché à nos conteneurs :
sudo docker-compose -f create-certs.yml run --rm create_certs
On peut maintenant passer au téléchargement des images:
sudo docker-compose pull
On peut maintenant démarrer les conteneurs, pour le premier démarrage, je vous conseille de ne pas utiliser le paramètre -d afin d’avoir le retour (log) des conteneurs afin de s’assurer que tout fonctionne.
sudo dcoker-compose up

Une fois les conteneurs démarrés, ce qui peut prendre 5 minutes, ouvrir un navigateur Internet et entrer comme adresse : https:/server_ip:5601 ou https://dns_name:5601 pour accéder à l’interface Web de Kibana.
Comme on utilise un certificat autosigné, il est nécessaire de forcer l’alerte de sécurité.
Patienter pendant le chargement …

Sur le formulaire d’authentification, en Username saisir elastic et en mot de passe, celui qui a été configuré dans le fichier .env.
A la première connexion, Elastic vous propose d’ajouter des éléments, cliquer sur Explore on my own.
On arrive ensuite sur une page où l’on peut voir les différents éléments que l’on peut integrer dans ELK.
Avant de redémarrer notre conteneur normalement, vu que tout fonctionne correctement, on va activer le monitoring de notre cluster.
Cliquer sur le bouton du menu 1 puis sur Stack Monitoring 2.
L’assistant nous propose de passer par l’agent Metricbeat, cliquer sur Or, sert up with self monitoring 1.
Pour rappel, Elasticsearch et Kibana sont en conteneurs, ce qui impliquerait d’installer l’agent Metricbeat dans les images, chose à ne pas faire.
Cliquer sur le bouton Turn on monitoring 1.
Une fois le monitoring activé, laisser sélectionner Yes 1 pour créer les règles par défaut et cliquer sur OK 2.
On a des informations sur l’état du cluster Elasticsearch et Kibana.
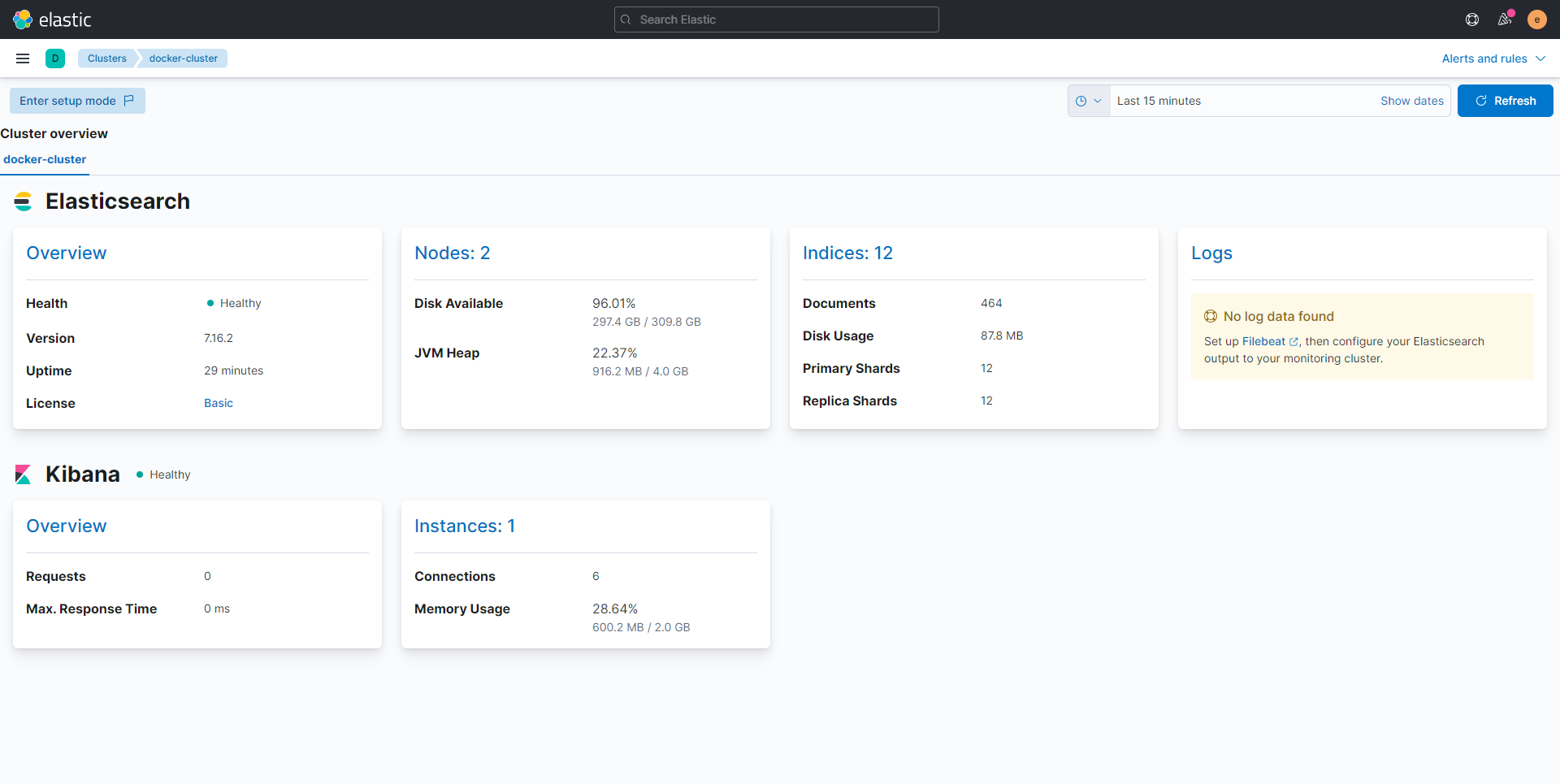
L’espace disque est doublé, car il prend l’espace disque visible pour chaque nœud du cluster, les données étant enregistré deux fois, cette espace disque réduit dans les même proportion.
Maintenant retourner sur le terminal, arrêter le stack de conteneur avec les touches Ctrl+C, une fois arrêté, redémarrer les conteneurs avec la commande :
sudo docker-compose up -dAvant de passer à la suite, je vous conseille de retourner sur l’interface Web et de faire le tour du menu pour commencer à vous familiarisez avec l’interface Web et éveiller votre curiosité
Installation de Logstash
Avant de pouvoir envoyer des logs à Elascticsearch, nous allons passer à l’image du conteneur Logstash.
Si vous avez utiliser le dépôt sans Logstash, vous trouverez ici les fichiers pour pour créer le conteneur Logstash.
Sur le dépôt que vous avez cloné, aller dans le dossier Logstash.
Avant de se lancer dans la création du conteneur, quelques explications sont nécessaires, notamment sur les fichiers qui se trouve dans le dossier pipeline
Comme pour EK, éditer le fichier .env pour configurer la version à utiliser.
Dans le dossier pipeline, on trouve deux fichiers de configuration (conf).
- 01-default-beats-input.conf : qui configure l’entrée des logs dans Logstash
- 99-default-beats-output.conf : qui indique où les logs sont envoyés c’est à dire vers Elasticsearch
Le fichier 01-default-beats-input.conf :
Ce fichier est simple, il indique à Logstash que l’on va recevoir des fichiers de beats (agents) sur le port 5044.
Le fichier 99-default-beats-output.conf :
Dans ce fichier, on indique à Logstash ce qu’il doit faire en sortie, il envoie au serveur Elasticseach les données, on peut voir également, que les informations d’identification sont configurés dans ce fichier.
La condition permet de détecter si un pipeline est configuré au niveau de l’agent et que celui-ci doit être détecté au niveau de Elasticsearch pour traiter l’information. Par exemple, si on envoie des logs Nginx ou Apache avec filebeat et que le module est activé, un pipeline sera mentionné, quand les données seront reçu sur Elasticsearch, celui-ci va savoir que c’est des logs de serveur Web et il va automatiquement jouer Geoip pour déterminer la provenance géographique du visiteur.
On indique également un Index où les données seront enregistrées, ici cela sera sous la format AgentBeat-VersionOfAgent-DateOfDay.
Si vous avez suivi, vous allez devoir éditer le fichier 99-default-beats-output.conf pour configurer, le serveur et le mot de passe du compte elastic.
Si vous avez utiliser le dépôt avec Elasticsearch / Logstash / Kibana, vous devriez seulement devoir configurer le mot de passe.
Maintenant que l’on est prêt , télécharger l’image Logstash :
sudo docker-compose pullAfin de vous s’assurer du bon fonctionnement et d’avoir le retour dans le terminal, démarrer le conteneur Logstash sans l’option -d.
sudo docker-compose up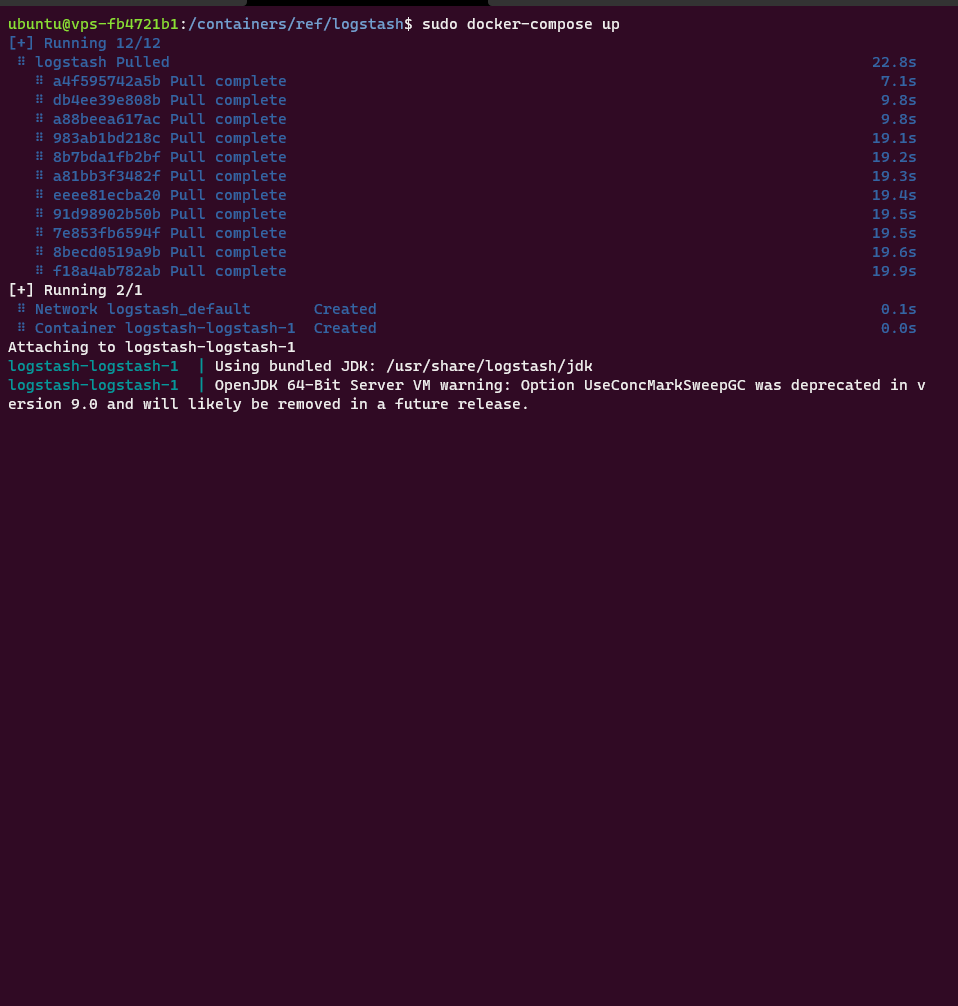
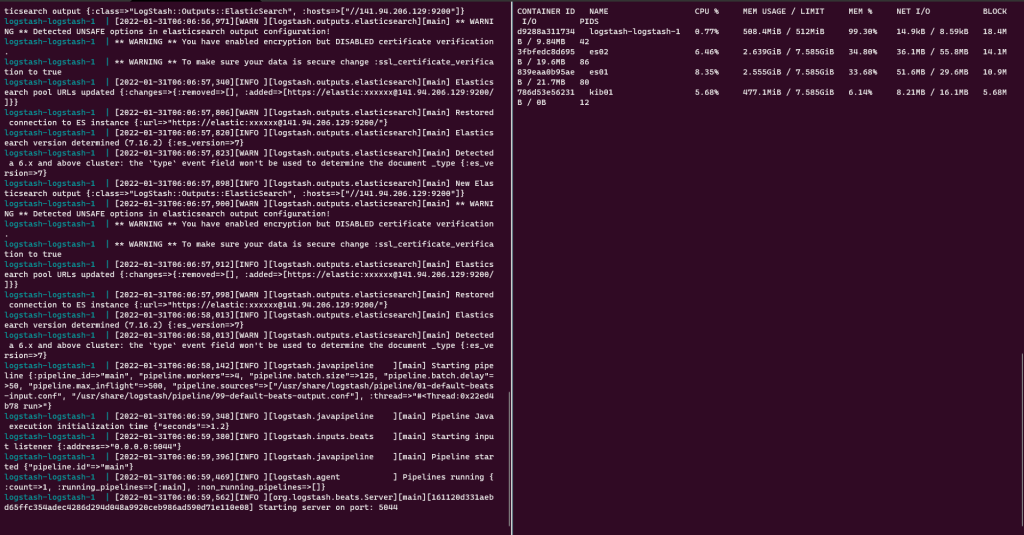
Si vous n’avez pas d’erreur et que le conteneur est démarré et que celui-ci ne redémarre pas, tout est bon.
Le seul moyen d’en être sur, ça va être de configurer un agent et voir si les logs remontent dans Elasticsearch.
Les agents – Beats pour ELK
Dernier composant nécessaire pour avoir des données, c’est les agents, je vais dans ce tutoriel, vous présenter deux agents :
- Filebeat qui est disponible sur Linux et Windows, son fonctionnement, c’est de lire des fichiers de logs et de les envoyer à Elasticsearch.
- Winlogbeat : disponible uniquement sur Windows , il va envoyer les enregistrements des journaux Windows à Elasticsearch.
Un agent que j’ai utilisé au début est Metricbeat, il permet d’envoyer les performances systèmes (CPU, Mémoire …) et les performances de certains applicatifs (Nginx, Docker …) à Elasticsearch et d’avoir des stats de performance
Si vous avez un outil de supervision type Zabbix, Metricbeat fait doublon et il est plus consommateur de ressource aussi bien sur l’hôtes où il est installé que sur la consommation de ressource sur le cluster ELK.
Filebeat
Dans ce tutoriel, je vais installer l’agent Filebeat sur un serveur Linux (Ubuntu).
Vous avez plusieurs solutions pour installer les agents sur Linux, sur Ubuntu / Debian, il est possible d’ajouter les dépôts et ensuite de faire l’installation avec apt.
Personnellement, je n’aime pas cette solution, car à chaque mise à jour de l’agent, il faut réinstaller les nouveaux pipelines et si vous faites les mises à jour de façon automatique avec Ansible par exemple, on perd la maitrise de l’environnement.
Sur cette page : https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-installation-configuration.html#installation , vous trouverez le lien et la commande pour télécharger et installer la dernière version disponible. Sinon vous trouverez ici : https://www.elastic.co/fr/downloads/past-releases les liens vers toutes les versions.
Télécharger l’agent :
CURL :
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.0-amd64.debWget :
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.0-amd64.deb
Une fois filebeat téléchargé, installer le :
sudo dpkg -i filebeat-7.17.0-amd64.deb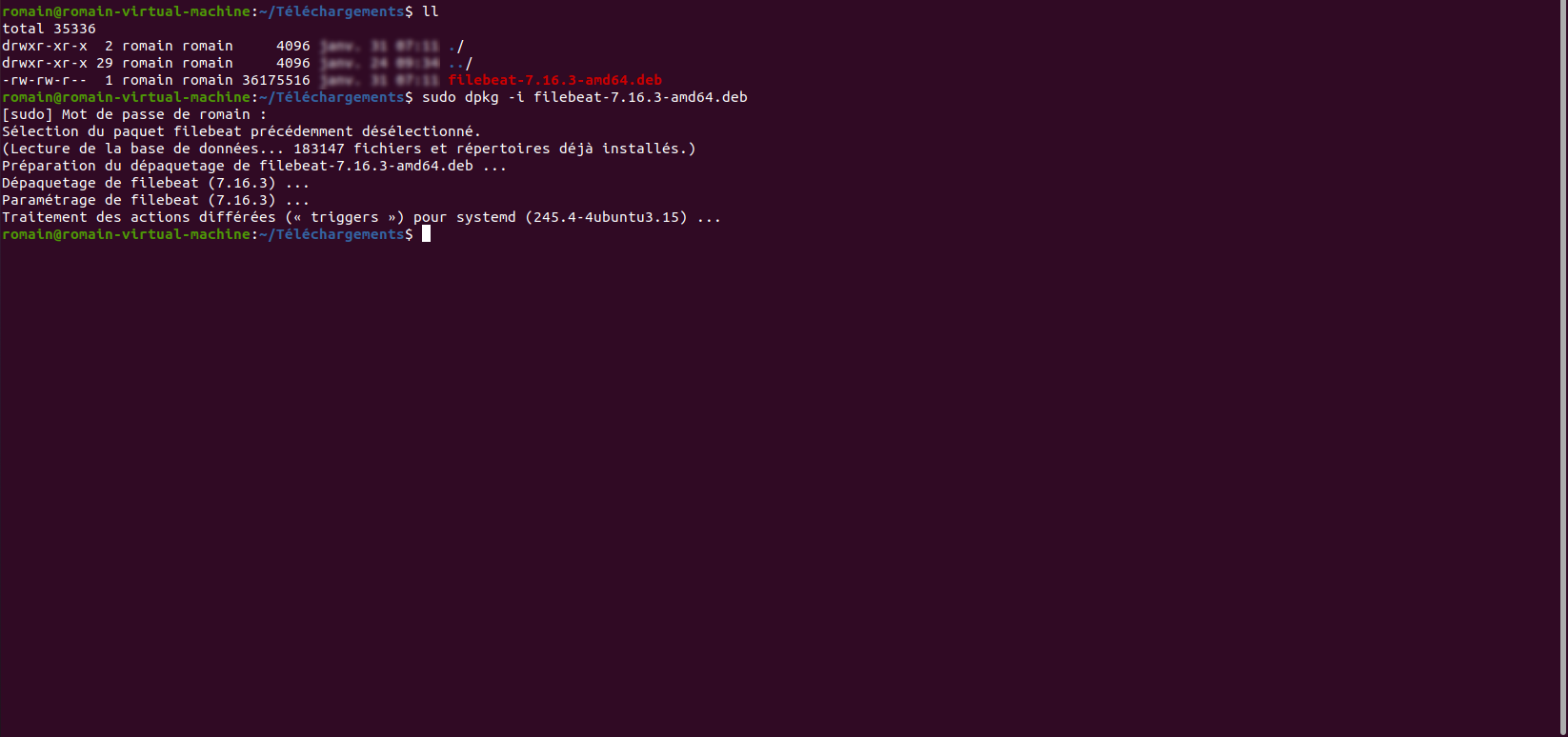
L’agent filebeat est installé, maintenant il va falloir faire plusieurs choses, avant de pouvoir envoyer des données.
Les modules Filebeat
L’agent filebeat dispose de plusieurs de modules qui permet de faciliter sa configuration.
Pour afficher les modules utiliser cette commande :
sudo filebeat modules list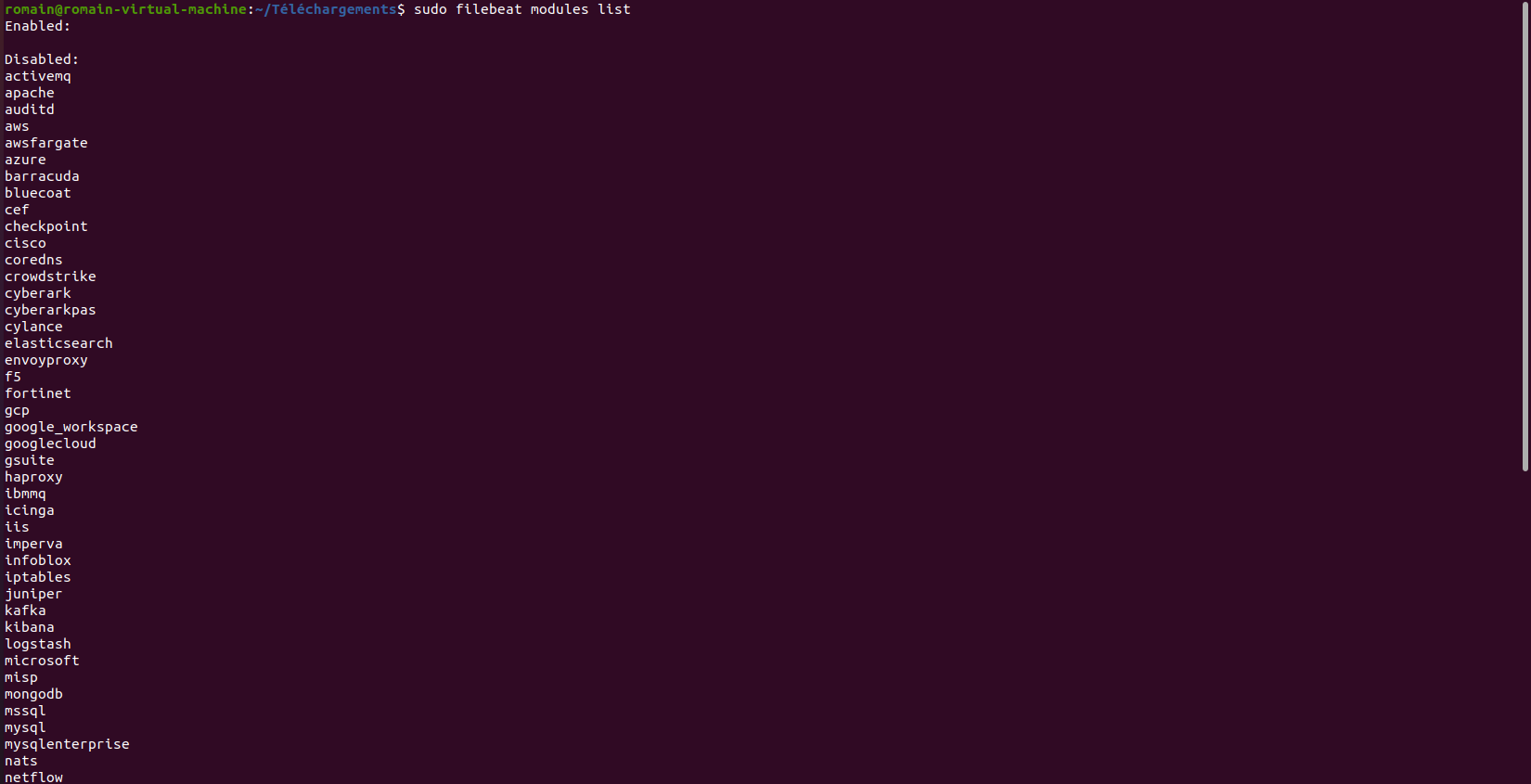
Pour activer un module :
sudo filebeat enable module_nameSur un Linux, on va à minima, activer le module system qui permet de collecter les logs du système d’exploitation (/var/log/syslog).
sudo filebeat enable systemPour désactiver un module si nécessaire
sudo filebeat disable module_nameA chaque installation de filebeat sur un serveur, il sera nécessaire de configurer les modules à utiliser
Initialisation des pipelines et tableau de bord de Filebeat
Maintenant, on va envoyer directement à Elasticsearch et Kibana, les pipelines et tableaux de bord de filebeat.
Cette manipulation est à faire mises à jour (changement de version) de l’agent Filebeat.
C’est peu lourd à faire, surtout qu’il y a des mises à jour régulièrement.
L’initialisation se fait au niveau de Elasticsearch et Kibana directement, il faut donc configurer l’agent pour communiquer directement avec notre cluster.
Editer le fichier de configuration de l’agent Filebeat :
sudo nano /etc/filebeat/filebeat.ymlDans le fichier recherche la section Outputs et configurer output.elasticsearch:
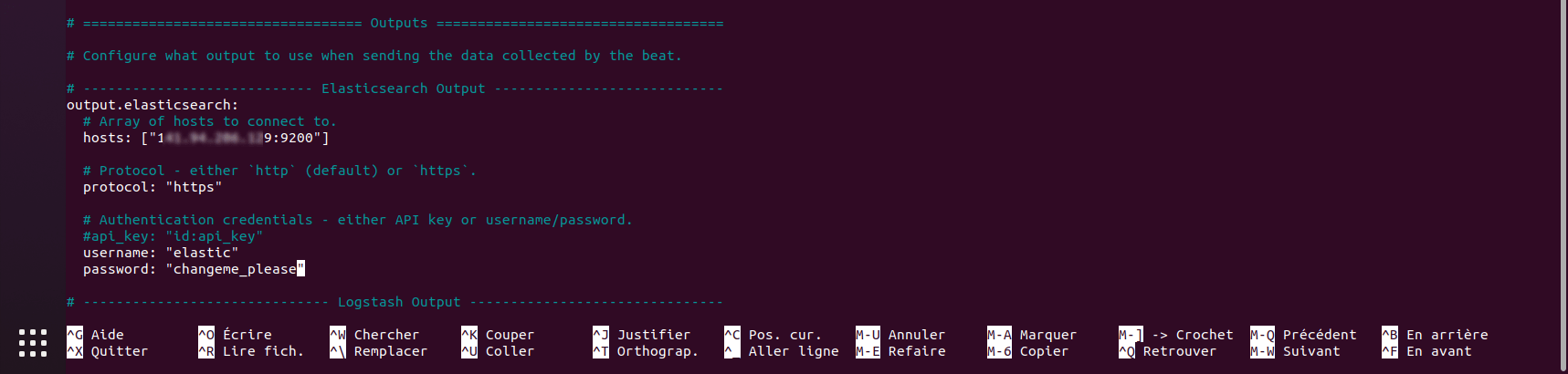
Faire de même pour la section Kibana:
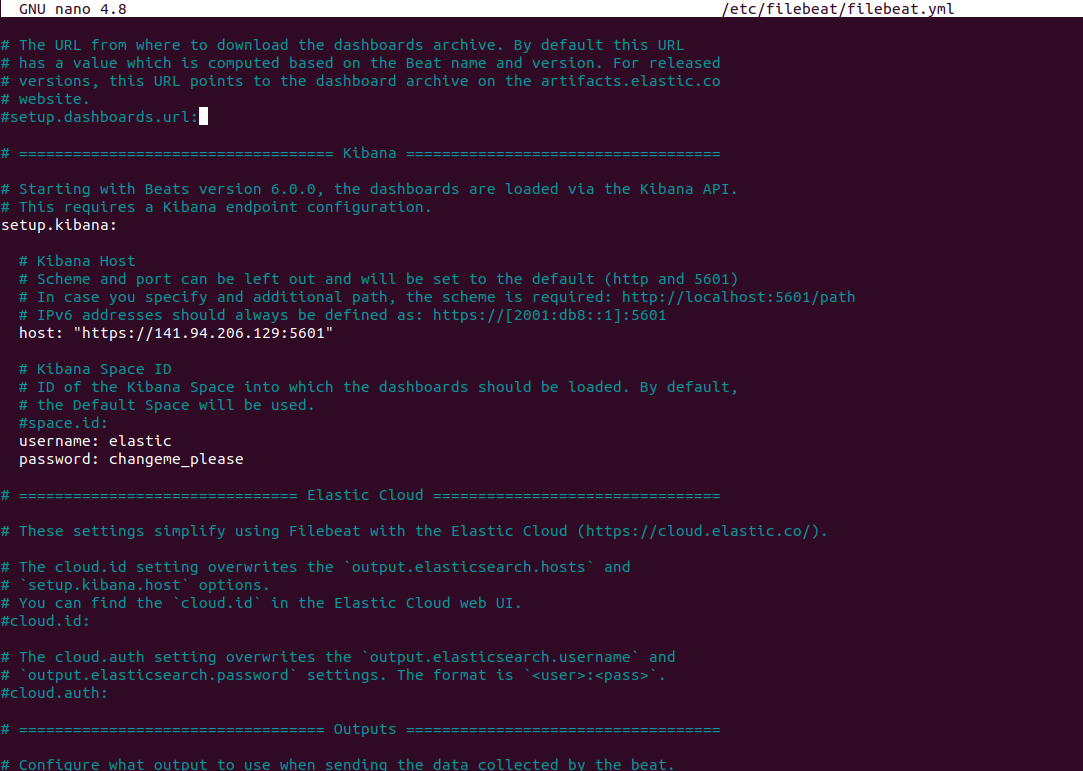
Aller à la fin du fichier et ajouter les lignes ci-dessous pour ignorer les erreurs de certificat SSL.
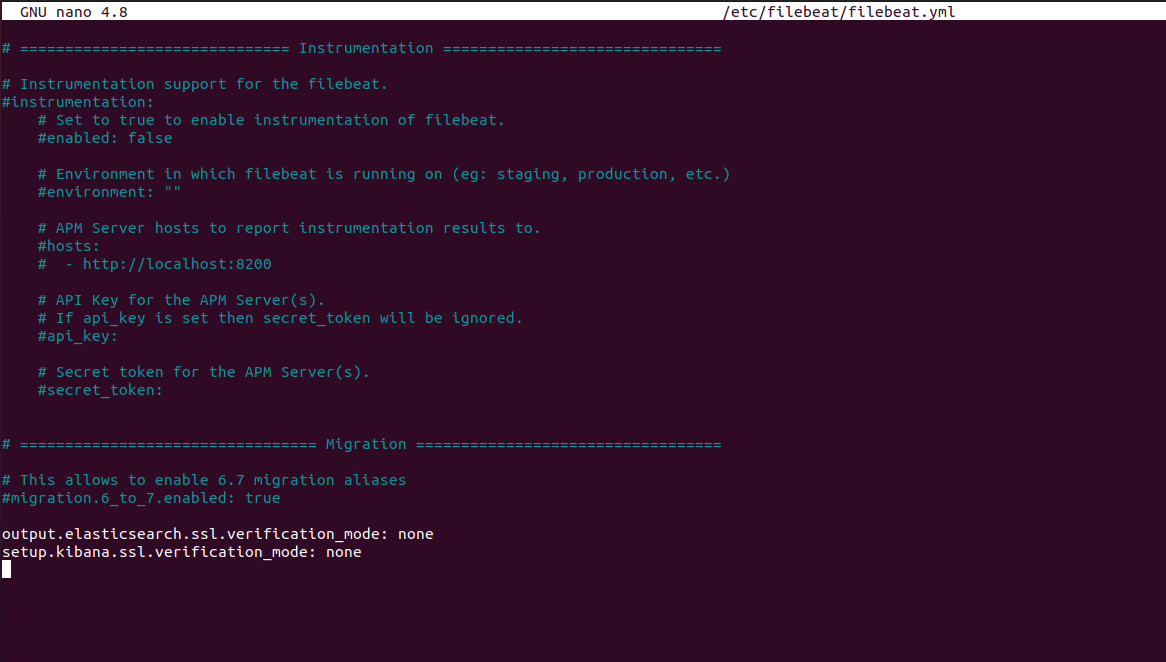
Sauvegarder le fichier.
On va maintenant passer à l’installation des pipelines dans ELK. Si vous comptez utiliser d’autre modules sur d’autre serveur avec l’agent Filebeat, je vous conseille de les activer maintenant, installer les pipelines et ensuite désactiver les modules.
Installer les pipelines :
sudo filebeat setup -e
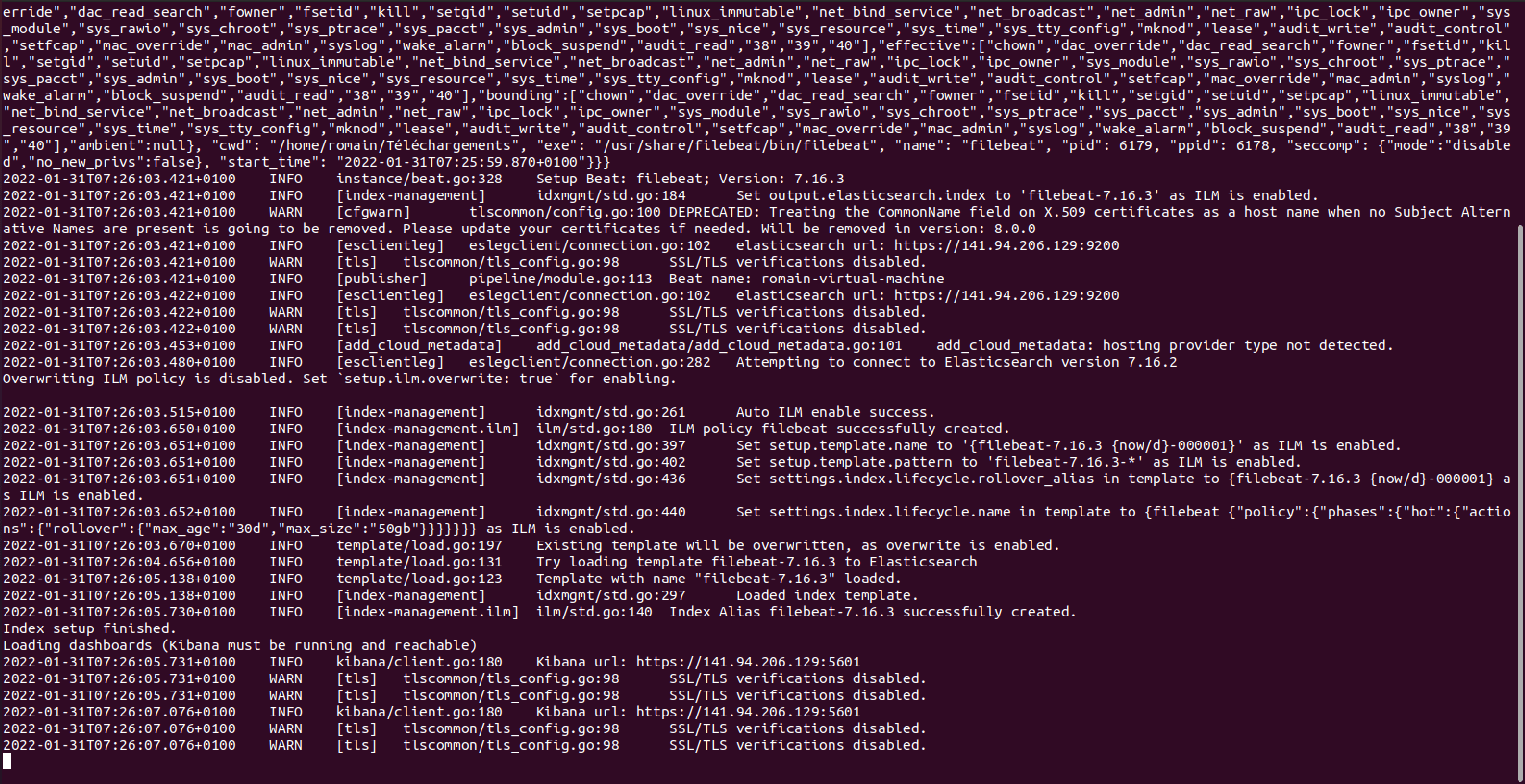
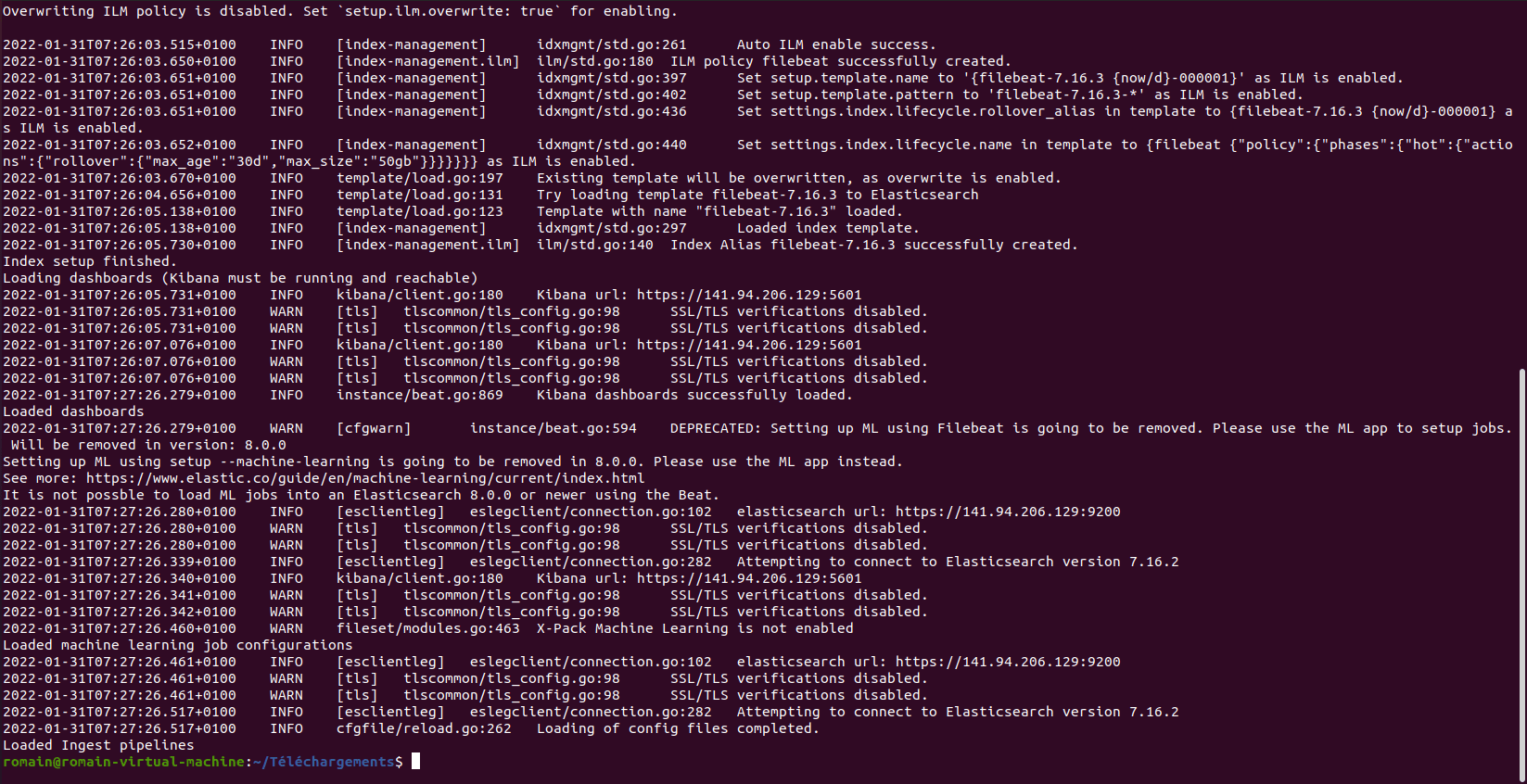
Cette commande permet d’installer les composants suivants au niveau de ELK :
- Configuration des index
- Configuration du cycle de vie (ILM)
- Installation des pipelines
- Le modèle au niveau de Kibana
- Les tableaux de bord
Il est possible d’ajouter les pipelines à l’aide la commande ci-dessous en indiquant les modules :
sudo filebeat setup --pipelines --modules system,nginx,mysqlPour ajouter les tableaux de bord entrer la commande ci-dessous :
sudo filebeat setup --dashboards
Les tableaux de bord dans Kibana :
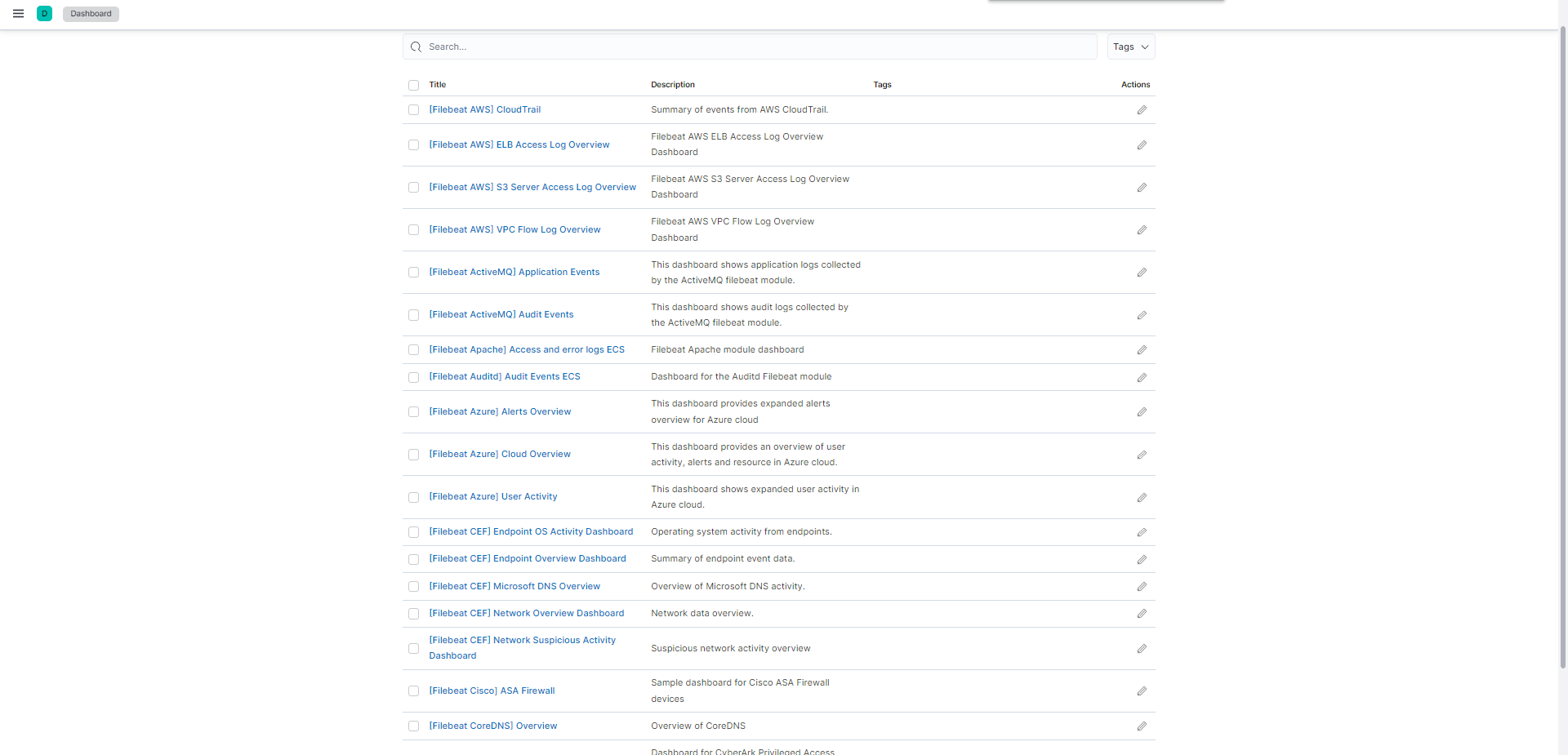
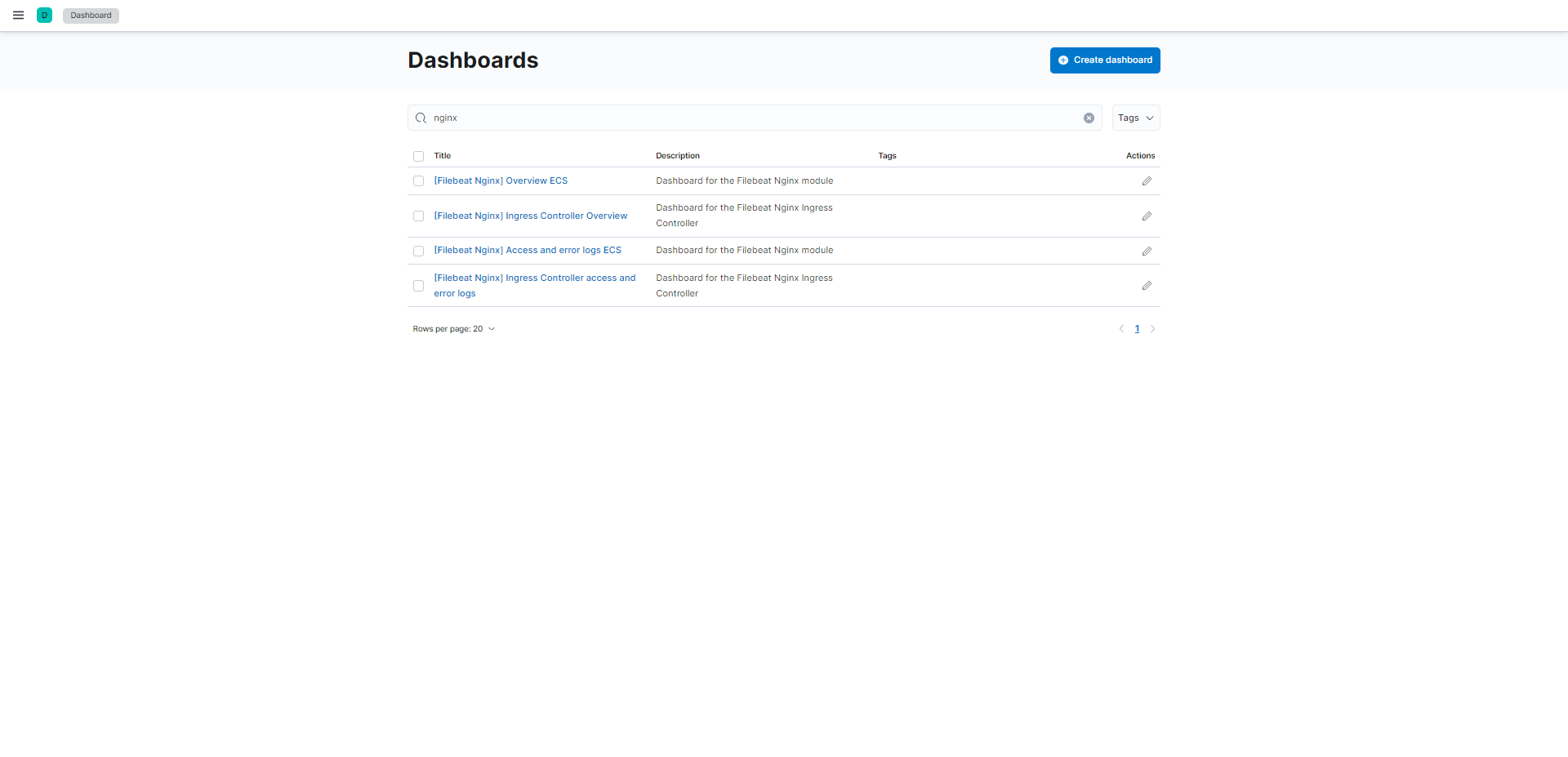
C’est bon, nous avons initialiser les éléments nécessaires pour Filebeat dans Elasticsearch et Kibana .
Ouvrir de nouveau le fichier filebeat.yml et commenter les lignes output.elasticsearch et setup.kibana.
Il est possible également de faire cette manipulation avec la configuration définitive, c’est à dire avec output.logstash de configurer : https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-template.html#load-template-manually
Configuration de l’envoie des logs à Logstash
Nous allons maintenant configurer filebeat pour envoyer les logs à Logstash.
Toujours dans le fichier filebeat.yml chercher la partie Logstash Output, décommenter output.logstash et configurer l’hôte Logstash :

Sauvegarder et fermer le fichier filebeat.yml
Configurer le service Filebeat
Il ne reste plus qu’à activer le service filebeat et le démarer.
Activer le service :
sudo systemctl enable filebeatDémarer le service :
sudo systemctl start filebeatMaintenant si tout fonctionne bien les logs devraient commencer à être envoyer à Logstash puis à Elasticsearch..
Dans le terminal où vous avez démarré le conteneur Logstash, vous devriez voir les logs passés.
Visualiser les logs dans Kibana
Depuis le menu, aller sur Discover, choisir le modèle Filebeat, normalement vous devriez voir les logs.

Si vous suiviez le tutoriel pas à pas, dans votre terminal arrêter le conteneur Logstash et redémarrer avec l’option détaché :
sudo docker-compsoe up -d
Metricbeat
Si vous souhaitez utiliser Metricbeat, l’installation, la configuration est identique que pour Filebeat. Metricbeat utilise également différents modules en fonction des éléments à superviser.
https://www.elastic.co/fr/beats/metricbeat
Winlogbeat
Maintenant, on va voir comment installer et configurer Winlogbeat pour collecter les évènements Windows.
Les explications que je vais donner pour Winlogbeat peuvent s’appliquer aussi à Filebeat et Metricbeat pour Windows.
Télécharger Winlogbeat : https://www.elastic.co/fr/downloads/beats/winlogbeat, je vous conseille d’utiliser la version Zip.
Une fois télécharger, décompresser l’archive et placer les fichiers à l’endroit souhaité sur le serveur Windows.
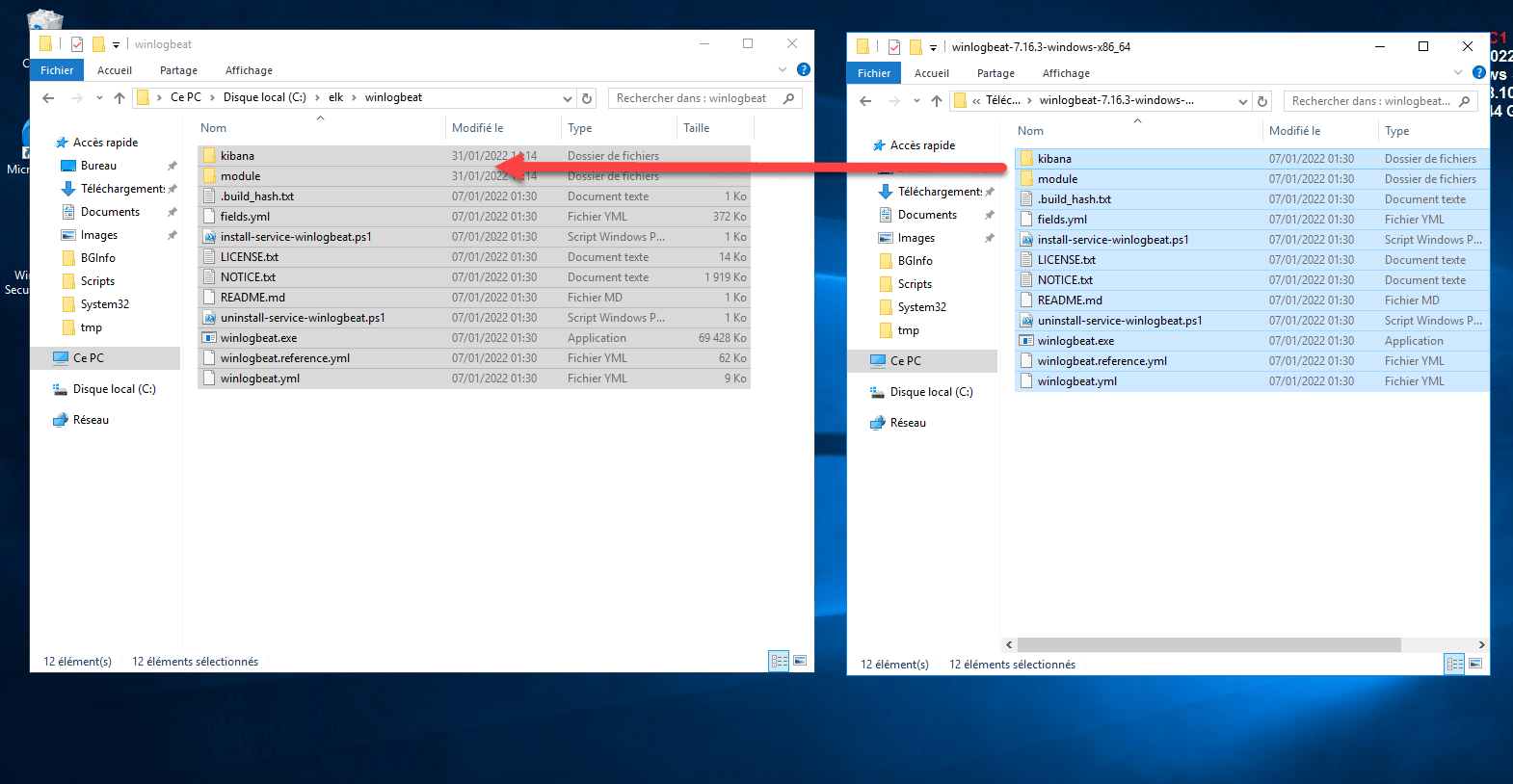
Ouvrir le fichier winlogbeat.yml.
Au début du fichier, on retrouve les journaux sont collectés.
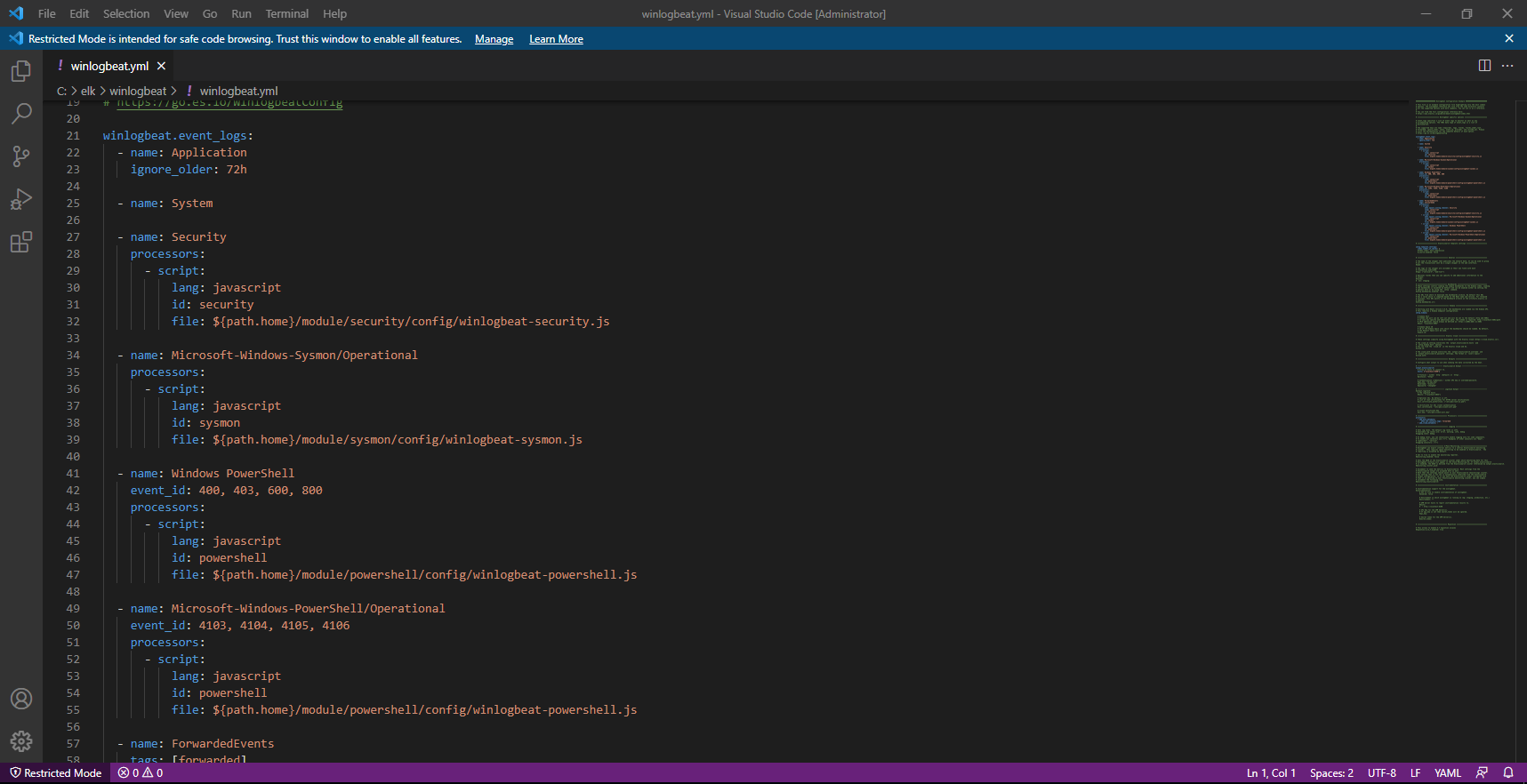
Il est possible d’ajouter d’autres journaux
Comment pour filebeat, il est nécessaire de configurer la partie outpout.elasticsearch et setup.kibana.
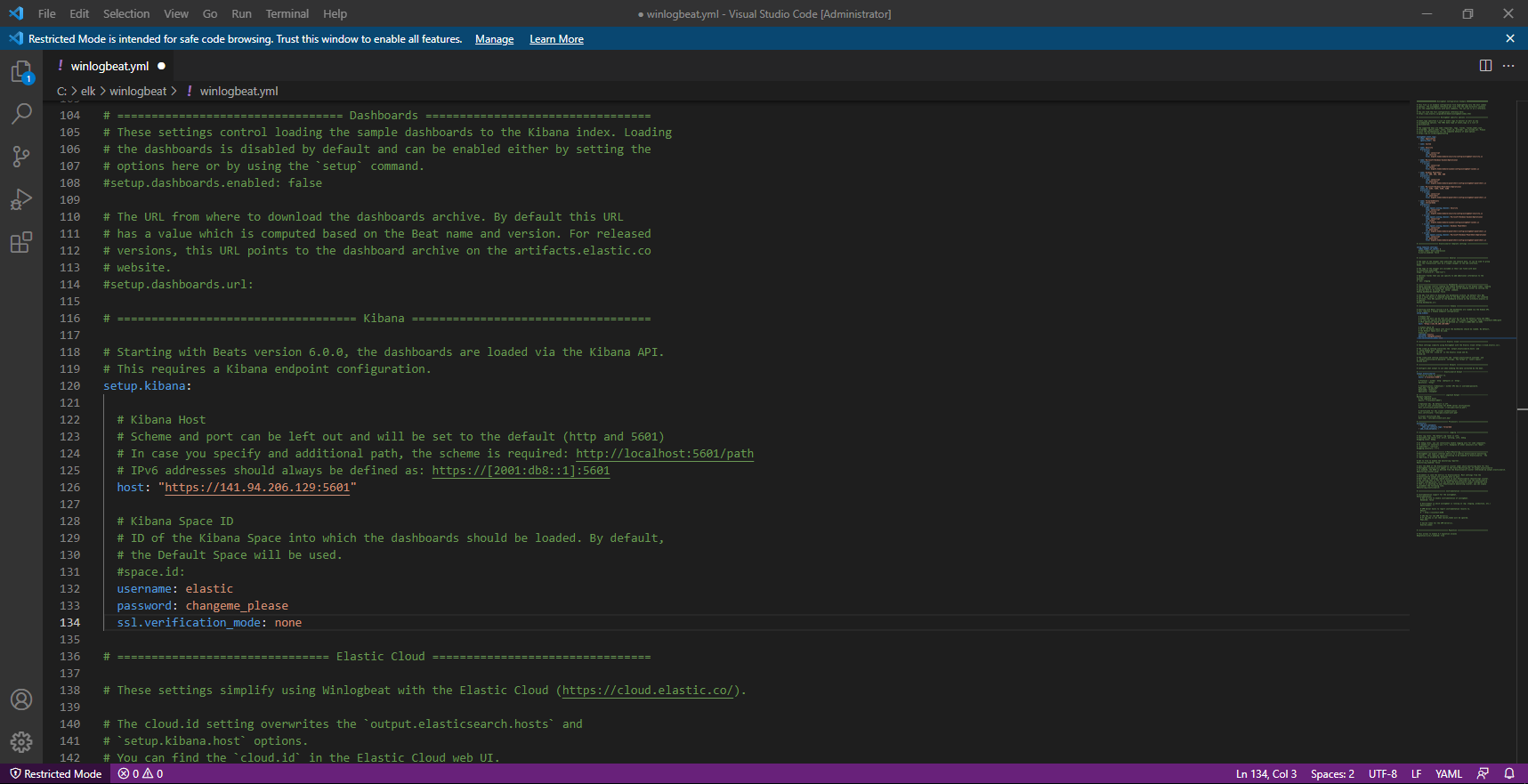
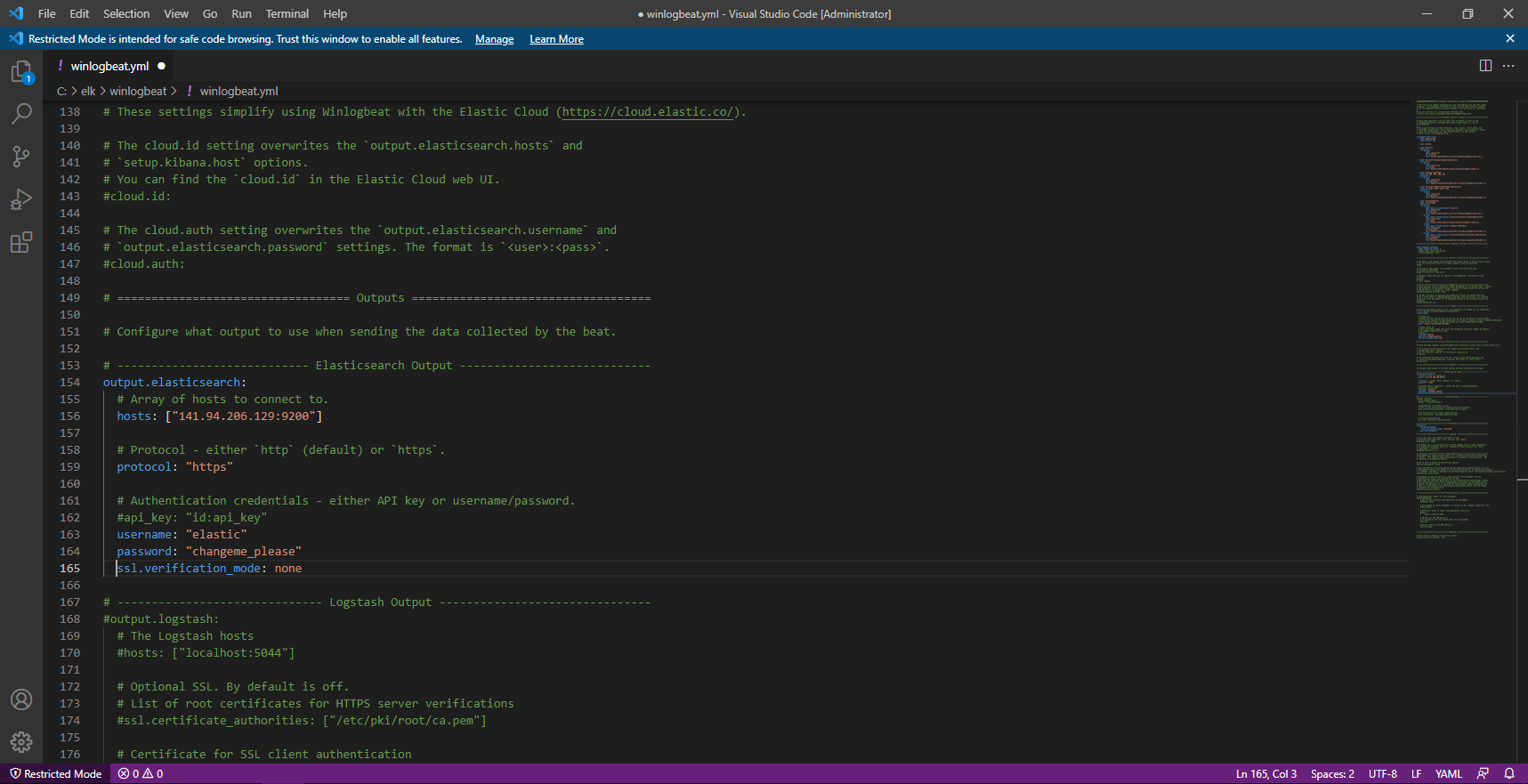
Je ne rentre pas dans les détails, car c’est exactement la même chose que pour Filebeat.
Pour les plus observateurs, vous pouvez voir sur les captures, que j’ai configuré la verification ssl au niveau de output.elasticsearch et setup.kibana.
Une fois le fichier édité, enregistrer le et fermer le.
Ouvrir un invite de commandes Powershell en Administrateur.
Aller dans le dossier de Winlogbeat :
cd c:\elk\winlogbeat
Installer l’index et la tableau de bord Winlogbeat dans ELK :
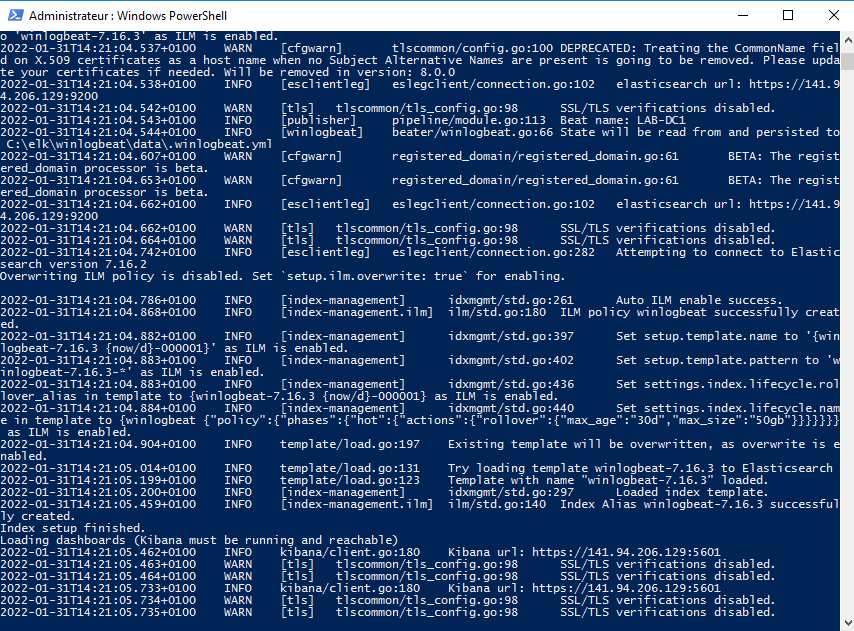
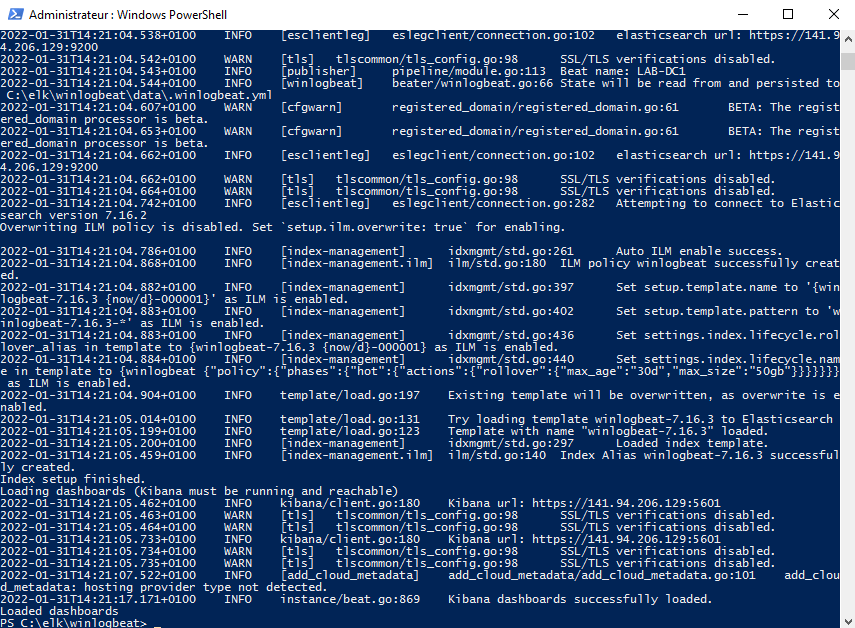
./winlogbeat.exe setup -e
Ouvrir de nouveau le fichier winlogbeat.yml et commenter la partie output.elasticsearch

Configurer la sortie vers Logstash

Enregistrer et fermer le fichier.
Retourne dans la fenêtre Powershell et exécuter le script pour installer le service :
.\install-service-winlogbeat.ps1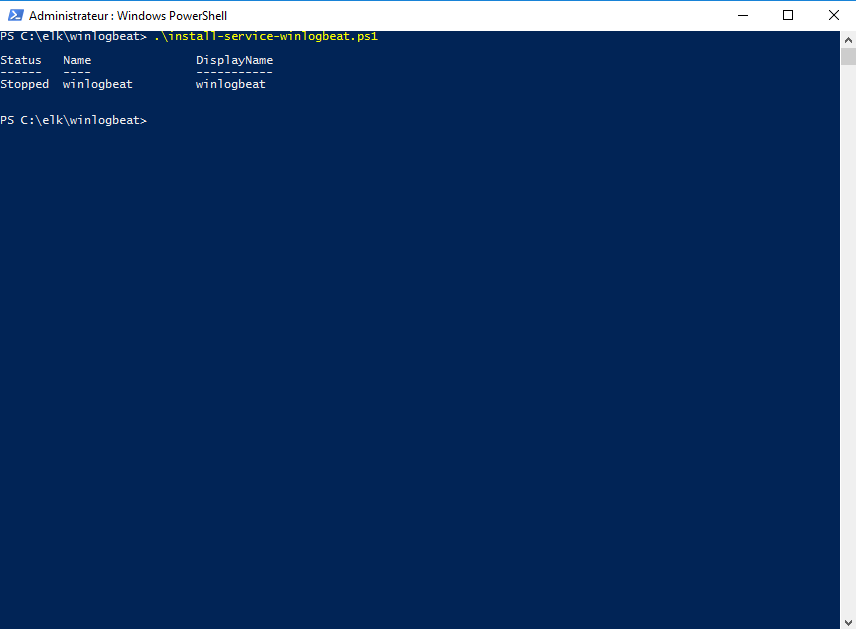
Démarrer le service :
Start-Service winlogbeatLes entrés des journaux Windows devraient être visible dans ELK :
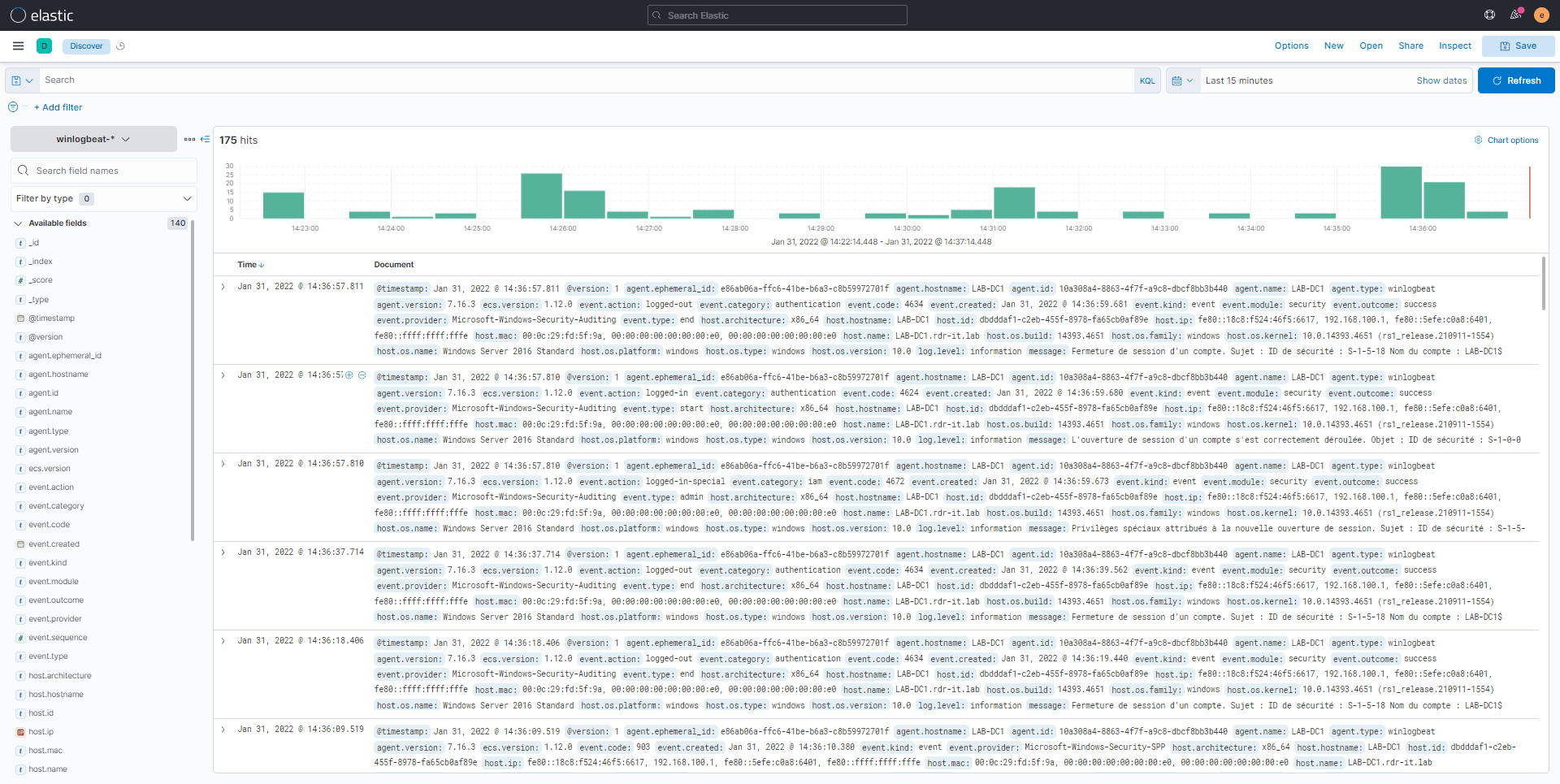
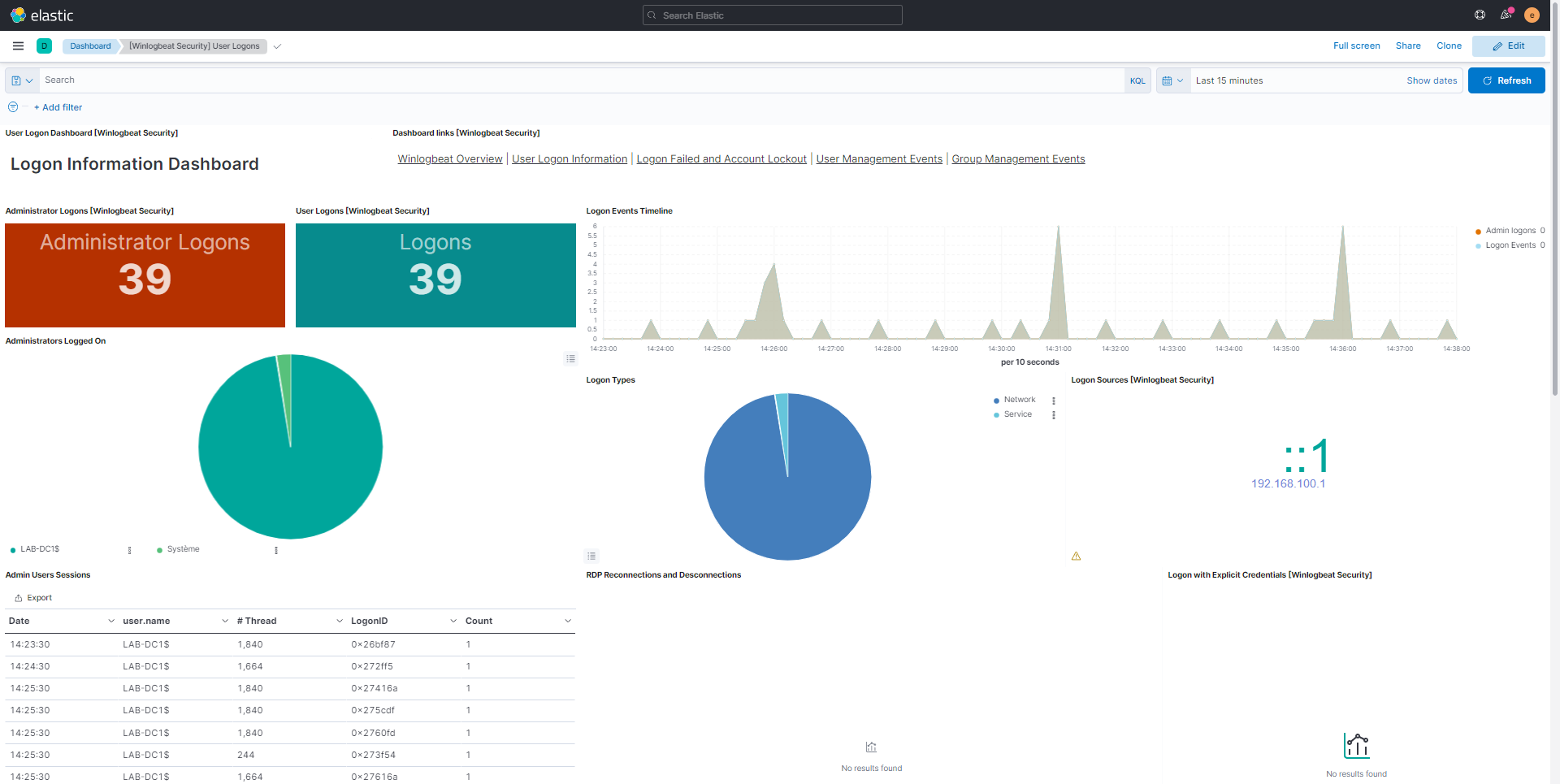
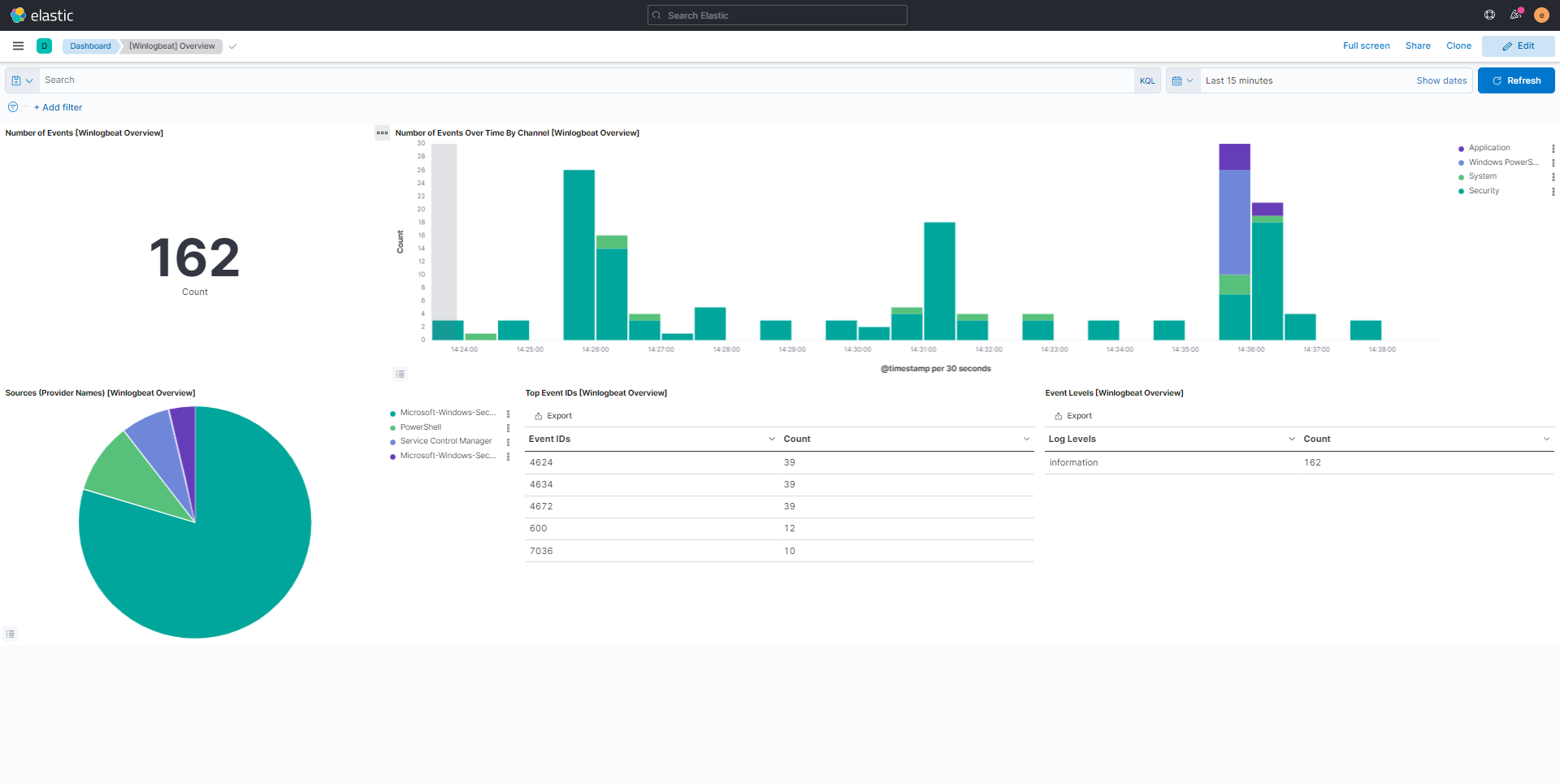
Pour finir ce tutoriel sur ELK
Ce premier tutoriel s’arrête ici et il y a encore beaucoup à voir aussi dans la configuration et l’utilisation de EL que de Logstash. D’autre tutoriel vont suivre sur points plus précis.
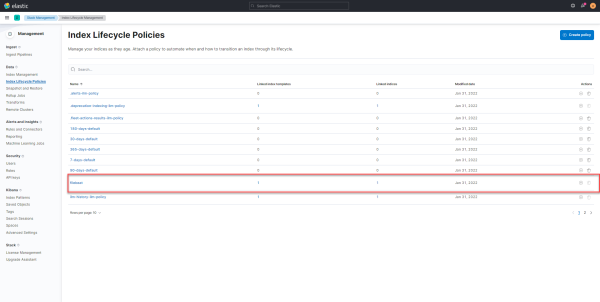
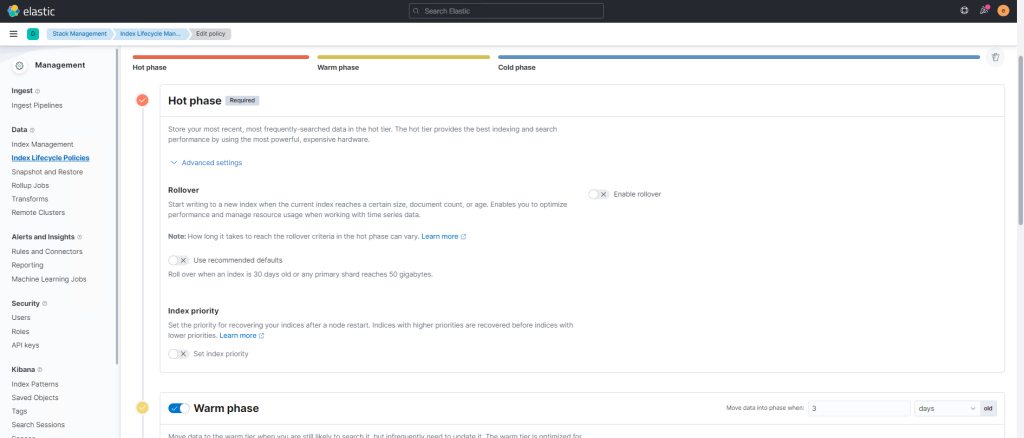
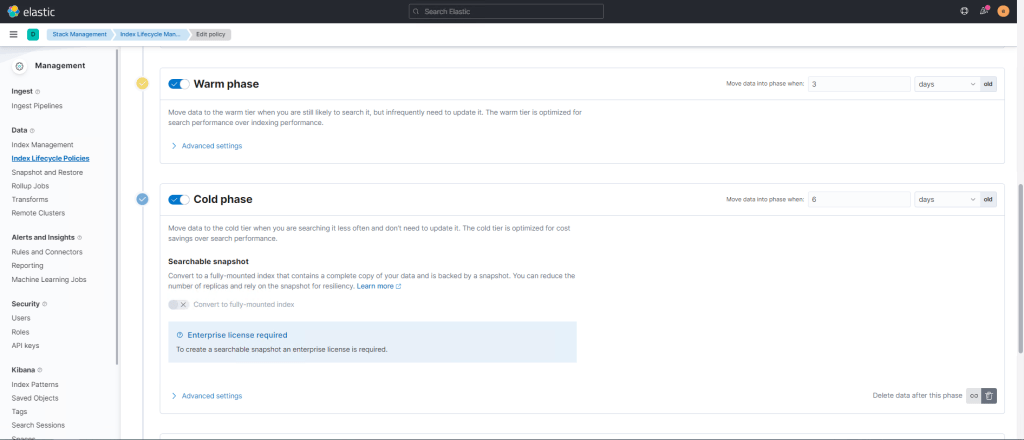
Ce que je peux vous conseiller de faire assez rapidement, c’est de configurer les stratégies de rétention des indices (Index Lifecycle Policies).
Dans cette configuration pour un bon fonctionnement, dans la partie Hot, désactiver le rollover, puis configurer la rétention de chaque phase.
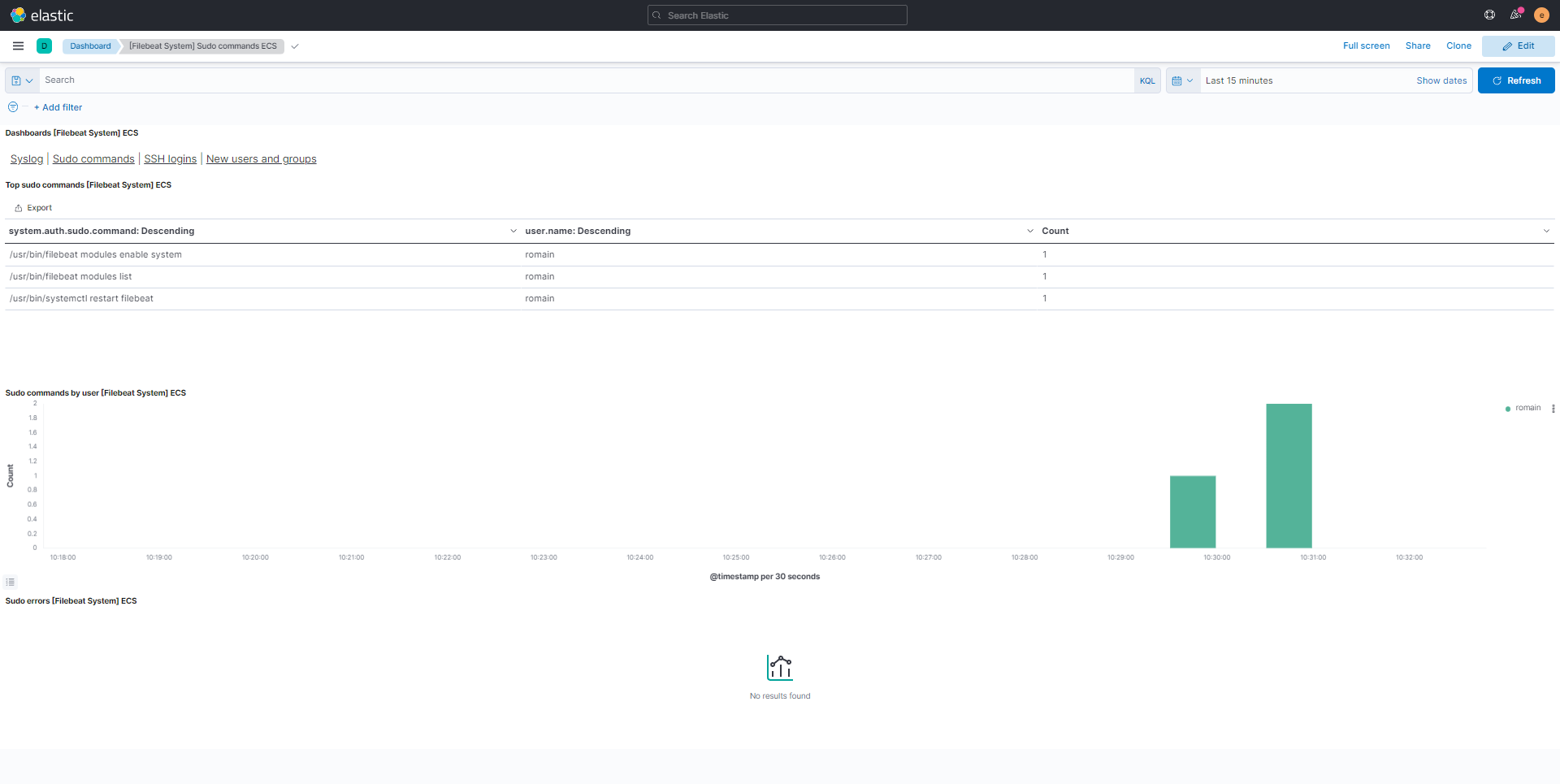
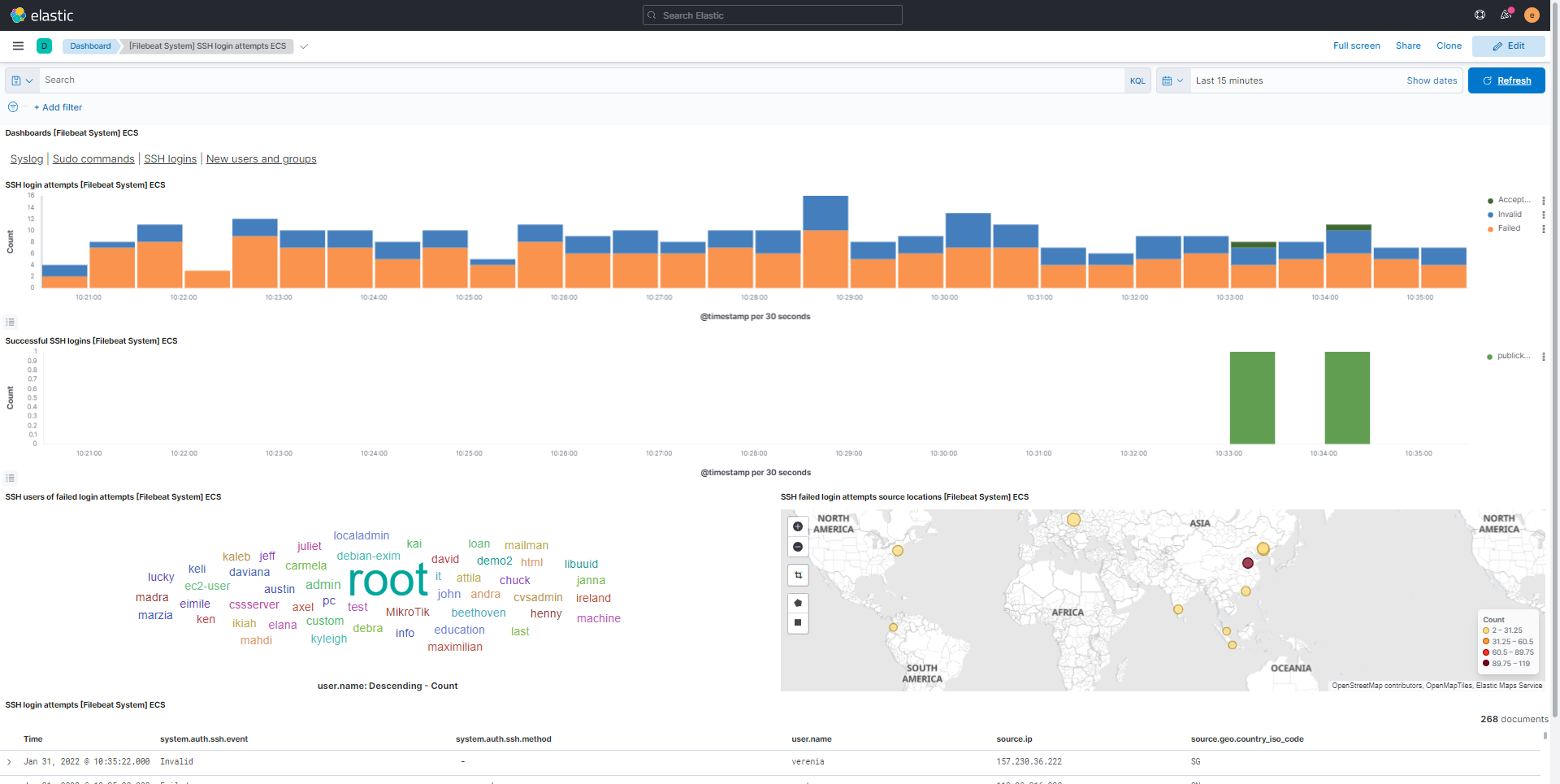
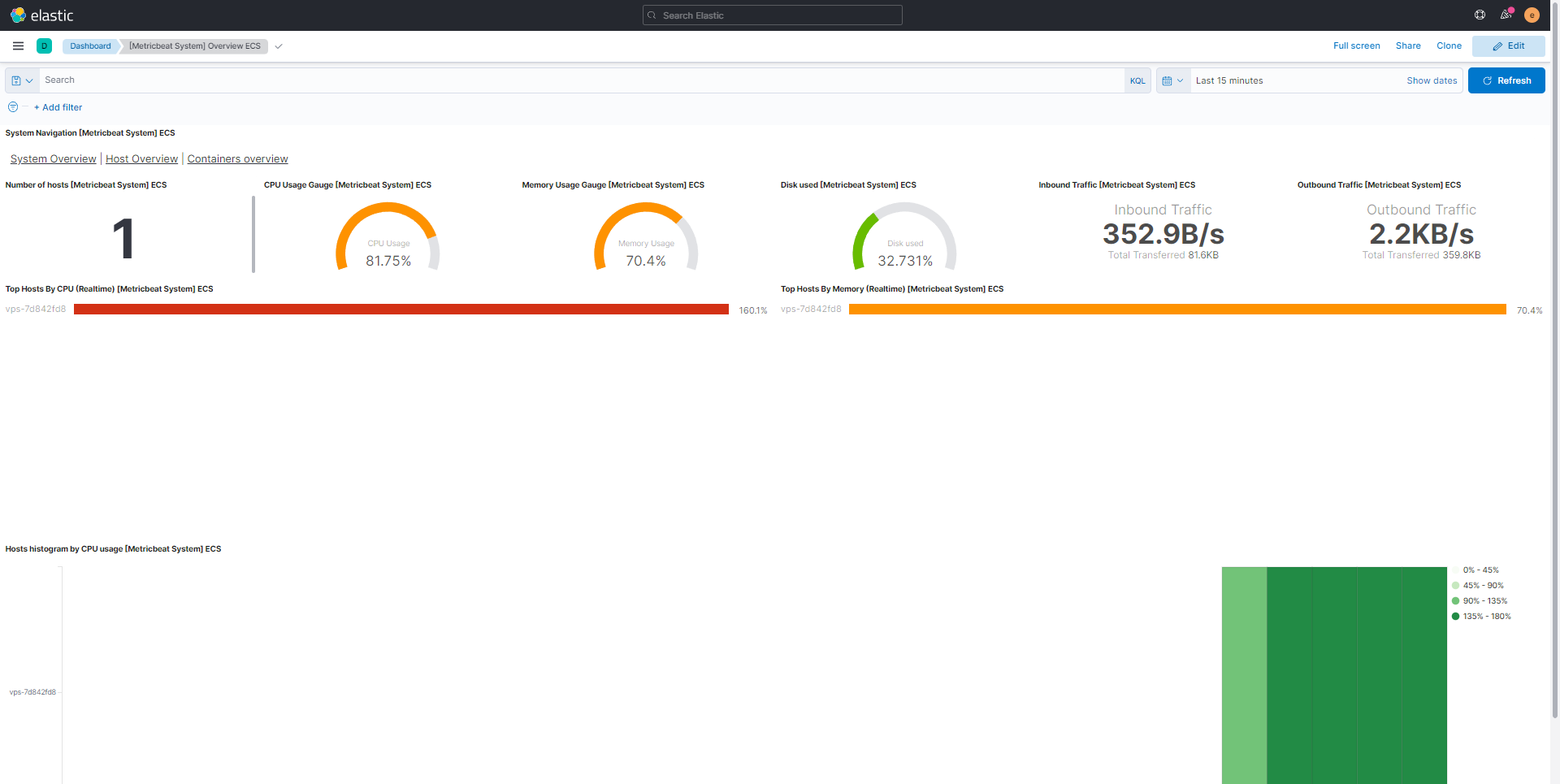
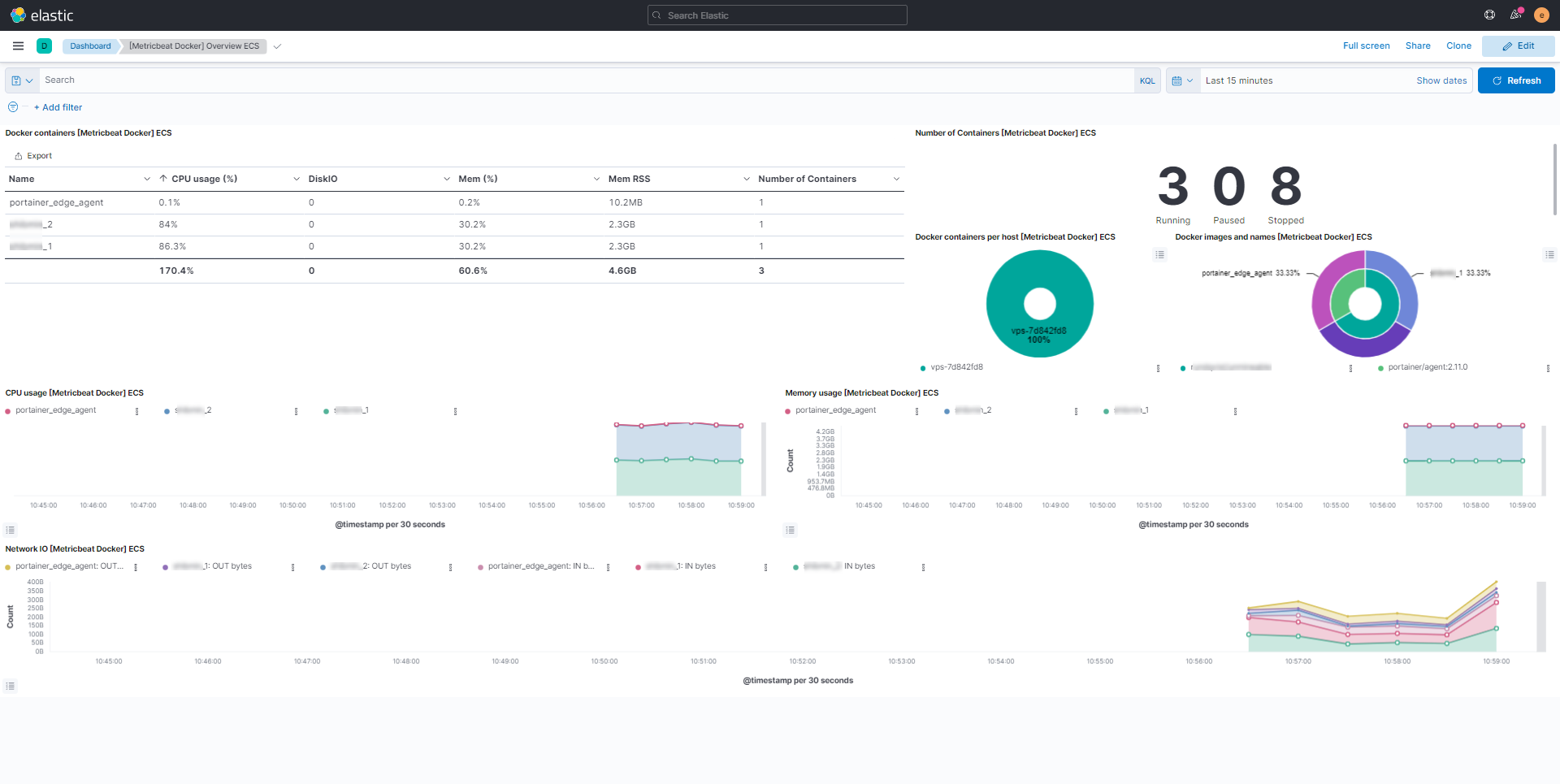
Je vous laisse sur quelques captures de tableau de bord afin vous donnez une idée des informations que vous pouvez avoir ELK.